📝 Paper Summary
Benchmark datasets
Multi-call tool use with flexible plan
Multi-task planning
TravelPlanner is a challenging benchmark that evaluates language agents on long-horizon travel planning with complex constraints, revealing that current LLMs struggle significantly with multi-constraint satisfaction.
Core Problem
Existing planning benchmarks focus on constrained settings with single objectives, whereas real-world planning requires handling long horizons, multiple interdependent decisions, and diverse constraints (commonsense, environmental, and user-specific).
Why it matters:
- Current agents fail in largely unconstrained settings where humans operate efficiently
- Prior benchmarks like Blocksworld are too simplistic to test the cognitive substrates needed for human-level planning
- Evaluating agents on multi-constraint tasks is crucial for deploying them in real-world scenarios like personal assistants
Concrete Example:
A user asks for a 3-day trip to Seattle with a specific budget and no seafood restaurants. Current agents might book a flight but fail to find a hotel within budget, or book a seafood restaurant, or schedule a flight on a day when none exists (hallucination).
Key Novelty
TravelPlanner Benchmark
- Provides a rich sandbox environment with 4 million real-world data entries (flights, hotels, restaurants) accessible via tools
- Features 1,225 meticulously curated queries with varying difficulty (Easy, Medium, Hard) based on travel duration and constraint complexity
- Introduces three distinct constraint types for evaluation: Environment (dynamic availability), Commonsense (logical travel rules), and Hard (specific user needs like budget)
Architecture
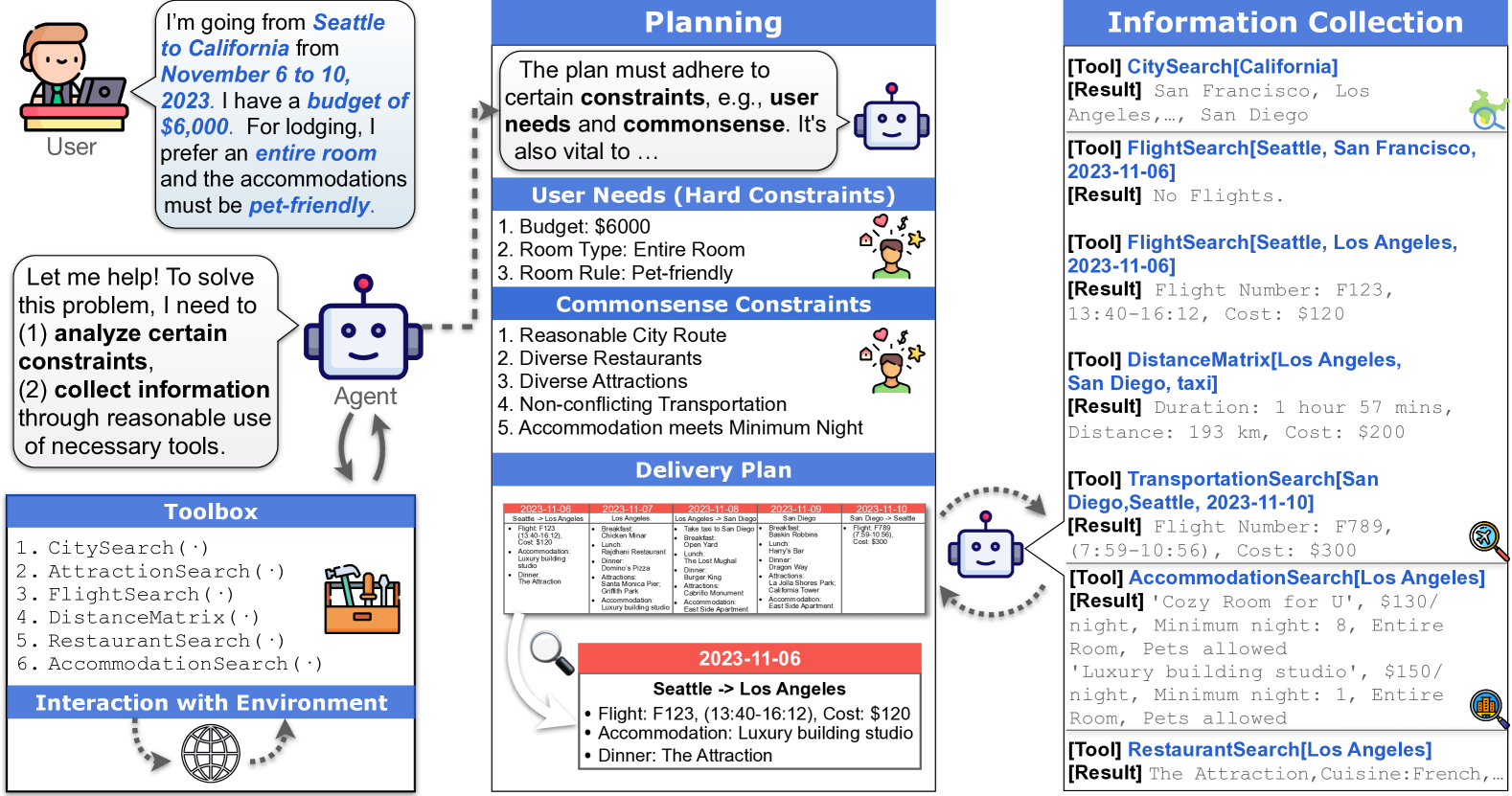
A visual example of a travel planning query, the constraints involved (environmental, commonsense, hard), and the iterative tool-use process required to solve it.
Evaluation Highlights
- GPT-4 only achieves a 0.6% success rate on the final pass rate (satisfying all constraints), indicating extreme difficulty for current SOTA models
- Human annotators take ~12 minutes per plan, while agents take 1-2 minutes but fail to produce feasible plans
- Sole-planning mode (tools removed, information provided) improves performance slightly but agents still struggle with constraint reasoning
Breakthrough Assessment
9/10
A significant reality check for the field. By exposing the near-zero success rate of GPT-4 on complex constraint planning, it establishes a new, necessary frontier for agent research beyond simple tool-use benchmarks.