📝 Paper Summary
Mathematical Reasoning
Instruction Tuning
Tool Use
MAmmoTH enhances mathematical reasoning in open-source LLMs by training on a curated hybrid dataset (MathInstruct) that combines natural language reasoning (CoT) with executable code generation (PoT).
Core Problem
Open-source LLMs lag significantly behind closed-source models (like GPT-4) in mathematical reasoning, and existing fine-tuning methods (like WizardMath) improve specific datasets but hurt generalization to out-of-domain tasks.
Why it matters:
- Current dataset-specific fine-tuning creates 'specialist' models that fail on broader math tasks (e.g., improving GSM8K but degrading AQuA accuracy)
- Chain-of-Thought (CoT) struggles with precise computation and complex algorithms, while Program-of-Thought (PoT) fails on abstract reasoning lacking API support
- Bridging the gap between open-source and closed-source models requires a lightweight approach that doesn't rely on expensive continued pre-training on 100B+ tokens
Concrete Example:
CoT prompts struggle to solve quadratic equations precisely, often making arithmetic errors. Pure PoT prompts fail on abstract algebra where no standard Python library exists. MAmmoTH switches between these strategies to solve both types effectively.
Key Novelty
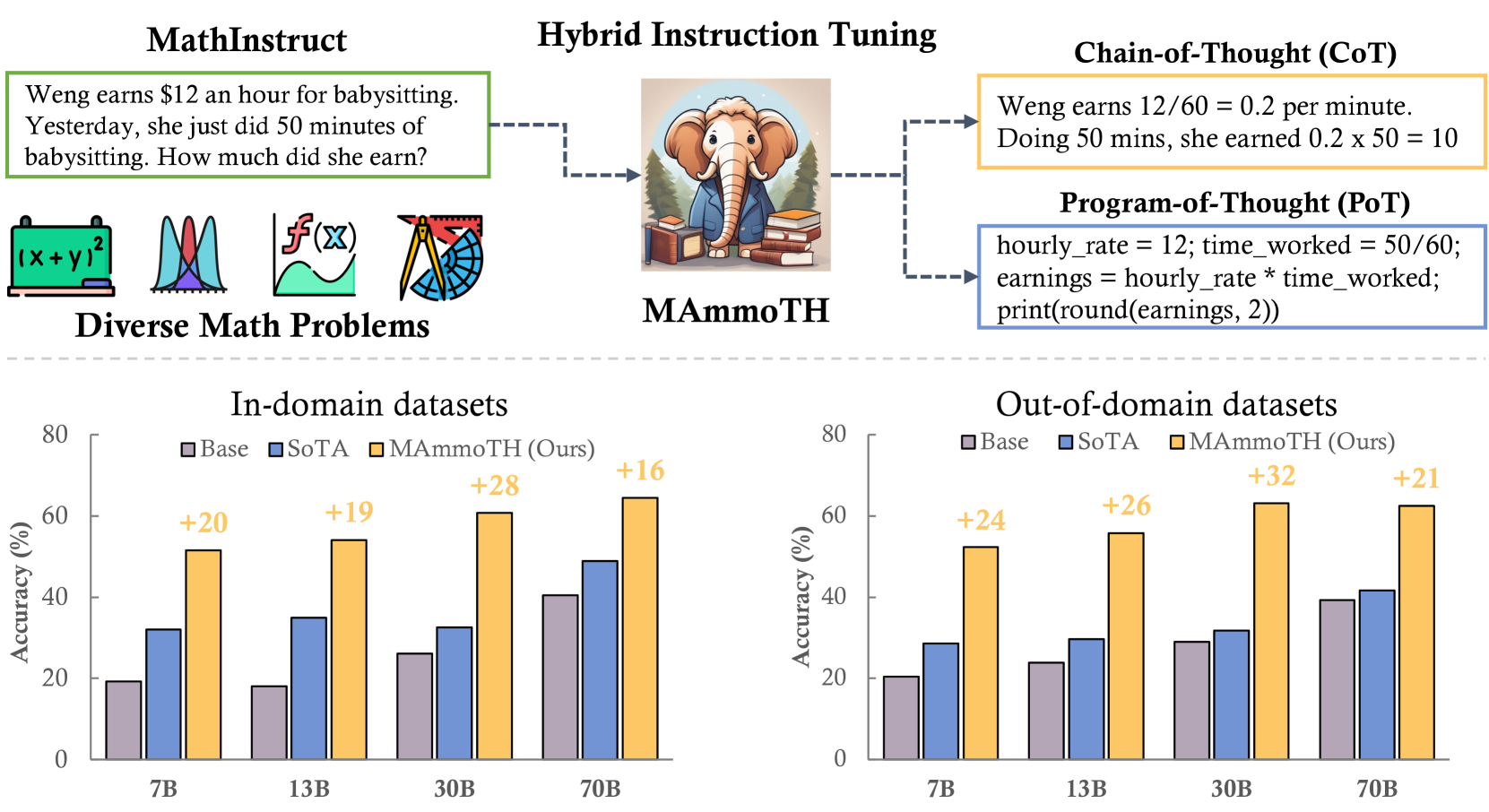
Hybrid Instruction Tuning with MathInstruct
- Curates 'MathInstruct', a dataset mixing 13 math datasets with both Chain-of-Thought (CoT) and Program-of-Thought (PoT) rationales to cover diverse math fields
- Trains models to be flexible: they can reason via text (CoT) for abstract concepts or write Python programs (PoT) for precise calculation
- Implements a hybrid decoding strategy during inference: first attempt to write and execute a program (PoT); if that fails, fall back to text-based reasoning (CoT)
Architecture
Overview of the MAmmoTH pipeline: constructing the MathInstruct dataset, fine-tuning base models, and the hybrid evaluation strategy.
Evaluation Highlights
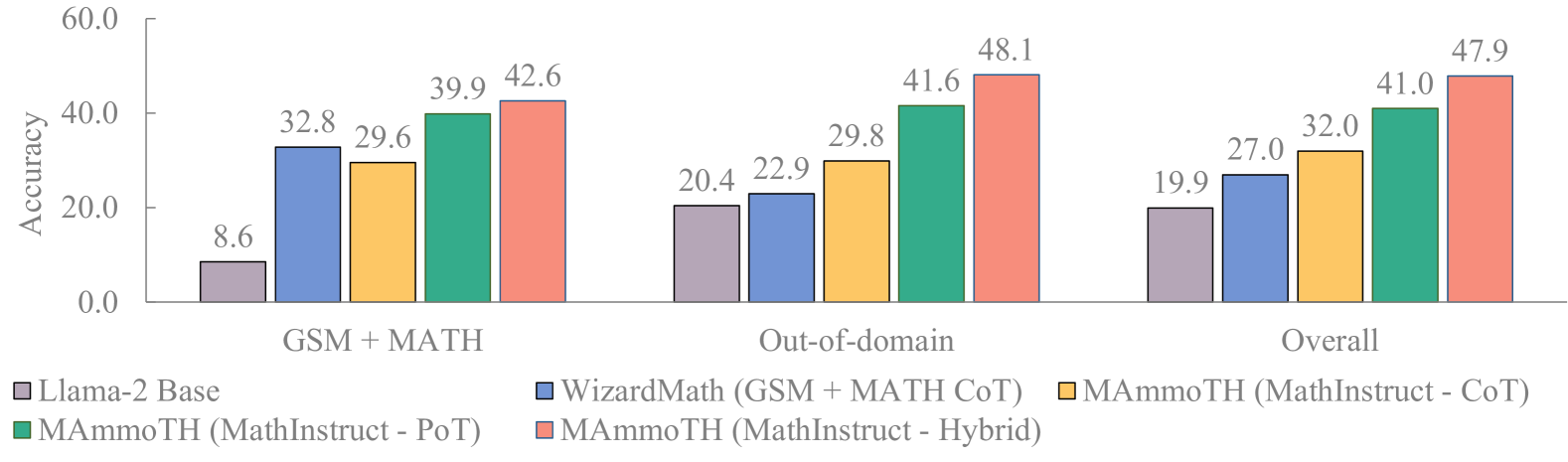
- MAmmoTH-7B achieves 35.2% accuracy on the competition-level MATH dataset, surpassing WizardMath-7B (10.7%) by over 3x
- MAmmoTH-Coder-34B achieves 44% accuracy on MATH, outperforming GPT-4's CoT result
- On out-of-domain (OOD) datasets, MAmmoTH models show 16% to 32% average accuracy gains compared to existing open-source baselines, proving better generalization
Breakthrough Assessment
9/10
MAmmoTH-Coder-34B beating GPT-4 (CoT) on MATH is a significant milestone for open-source models. The hybrid CoT/PoT approach effectively addresses the precision vs. reasoning trade-off.