📝 Paper Summary
Efficient Long-Context Attention
Agentic Reasoning
Reinforcement Learning for LLMs
DeepSeek-V3.2 introduces a sparse attention mechanism for efficient long-context processing and scales post-training RL compute with synthesized agentic data to rival top proprietary models.
Core Problem
Open-source models lag behind proprietary ones in complex tasks due to inefficient vanilla attention in long contexts, insufficient post-training compute, and poor generalization in agentic tool-use scenarios.
Why it matters:
- Vanilla attention's quadratic complexity limits efficiency and scalability for long sequences required in real-world applications
- Lack of sufficient post-training compute investment prevents open models from mastering hard reasoning tasks
- Existing open agents struggle with instruction following and generalization compared to closed models like GPT-5 or Gemini, hindering deployment
Concrete Example:
When simulating tool interactions (e.g., in Roo Code), standard models often discard reasoning history after a tool call, forcing redundant re-computation. DeepSeek-V3.2 retains reasoning context while managing token costs via sparse attention.
Key Novelty
DeepSeek Sparse Attention (DSA) & Scalable Agentic RL
- DSA uses a 'lightning indexer' to rapidly select relevant tokens for attention, reducing complexity from quadratic to near-linear while maintaining performance
- Integrates reasoning into tool-use via a massive synthetic pipeline (1,800+ environments) and a 'cold-start' phase that unifies chain-of-thought with tool calls
- Scales post-training RL compute to >10% of pre-training costs, using Group Relative Policy Optimization (GRPO) with novel stability fixes like Off-Policy Sequence Masking
Architecture
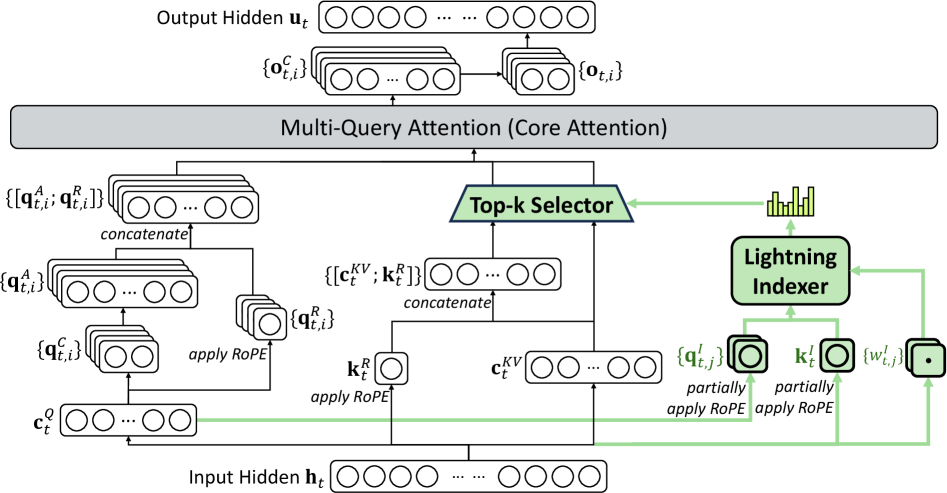
The DeepSeek Sparse Attention (DSA) architecture based on MLA (Multi-Head Latent Attention)
Evaluation Highlights
- DeepSeek-V3.2-Speciale achieves gold-medal performance in IMO 2025 and IOI 2025, matching Gemini-3.0-Pro
- DeepSeek-V3.2-Exp scores 4 points higher than DeepSeek-V3.1-Terminus on the AA-LCR long-context reasoning benchmark
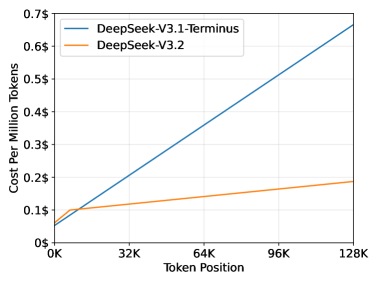
- Significant end-to-end speedup in long-context scenarios due to DSA reducing attention complexity from O(L^2) to O(Lk)
Breakthrough Assessment
9/10
Achieves parity with GPT-5 and Gemini-3.0-Pro in reasoning while significantly reducing inference costs via sparse attention. The massive scaling of post-training RL sets a new standard for open models.