📝 Paper Summary
Multi-call tool use with fixed plan
Multi-call tool use with flexible plan
ToolLLM empowers open-source LLMs to master thousands of diverse real-world APIs by fine-tuning on a large-scale, automatically constructed instruction dataset utilizing a depth-first search decision tree for reasoning.
Core Problem
Open-source LLMs lag behind closed-source models (like ChatGPT) in tool-use capabilities because current instruction tuning overlooks the tool domain and existing datasets are limited in API diversity and scenario complexity.
Why it matters:
- Existing open-source models struggle with complex instructions requiring the interplay of multiple real-world RESTful APIs.
- Prior datasets use limited scope or fake APIs, failing to stimulate generalizable tool-use capabilities.
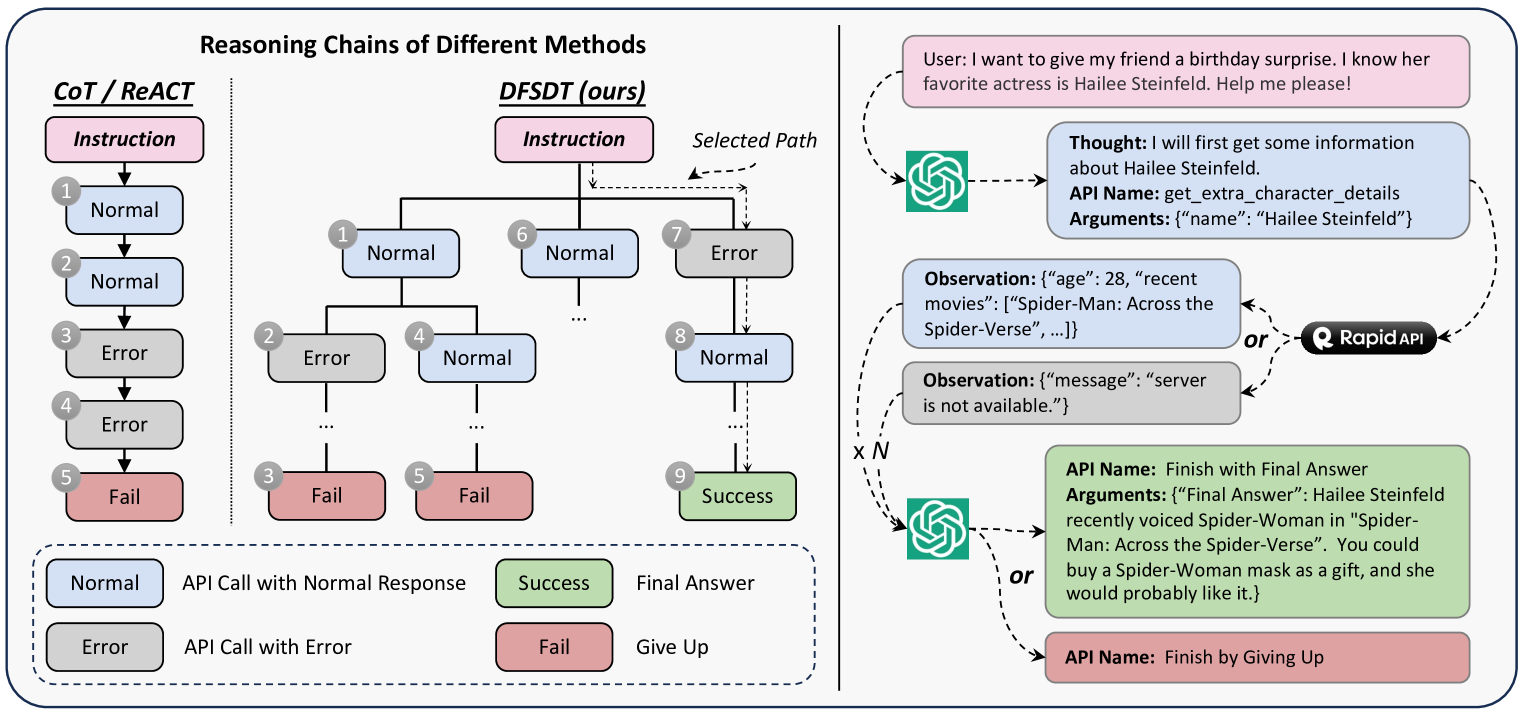
- Current reasoning strategies like ReACT or CoT suffer from error propagation and limited exploration when handling complex API interactions.
Concrete Example:
A complex instruction might require finding a movie, getting its rating, and then finding nearby theaters showing it. Standard ReACT might hallucinate an API or get stuck in a loop calling the wrong endpoint. ToolLLM uses a decision tree to backtrack and explore alternative API calls if the first attempt fails.
Key Novelty
ToolLLM Framework (ToolBench + ToolLLaMA + ToolEval)
- Constructs 'ToolBench', a massive instruction-tuning dataset derived from 16,464 real-world REST APIs using ChatGPT to generate instructions and solution paths.
- Introduces a Depth-First Search-based Decision Tree (DFSDT) to enhance planning, allowing the model to explore multiple reasoning paths and backtrack from dead ends during annotation.
- Trains a neural API retriever to handle massive API spaces, recommending relevant tools to the LLM rather than assuming they are known beforehand.
Architecture
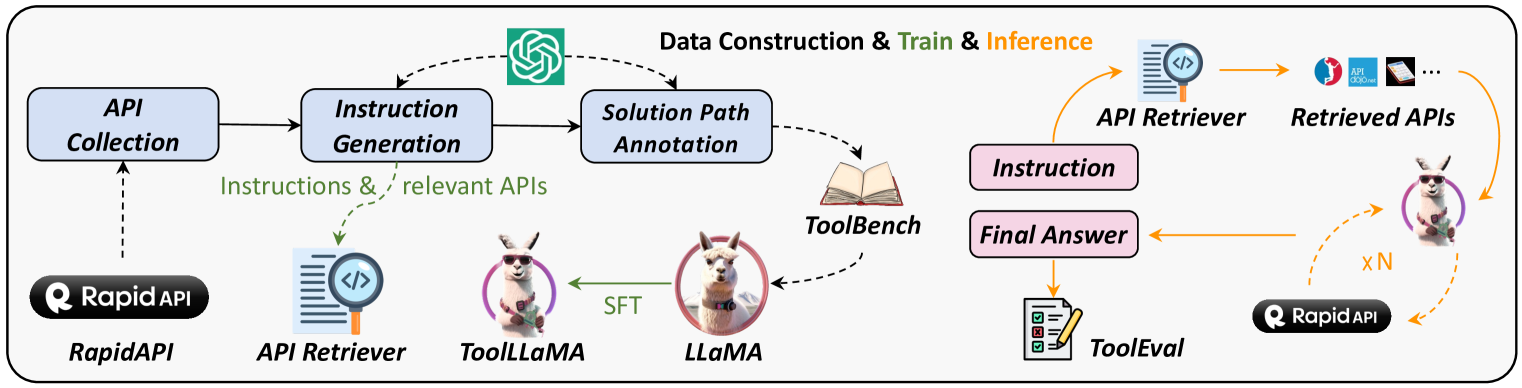
The overall ToolLLM framework, including the three stages of ToolBench construction (API Collection, Instruction Generation, Solution Path Annotation) and the inference process using ToolLLaMA with the API Retriever.
Evaluation Highlights
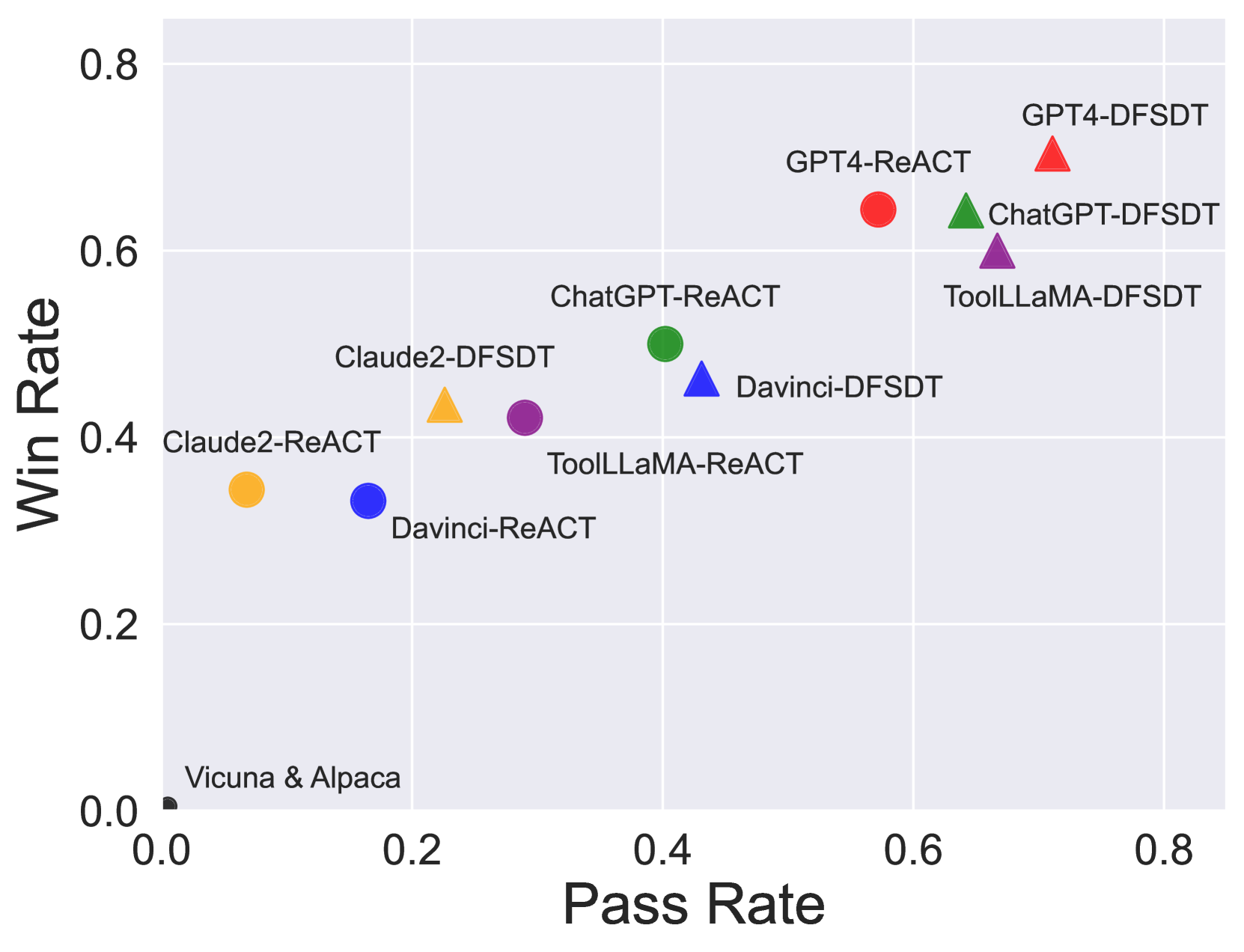
- ToolLLaMA demonstrates comparable performance to ChatGPT (the teacher model) on the ToolEval evaluation set.
- ToolLLaMA achieves strong zero-shot generalization on the out-of-distribution APIBench dataset, performing on par with Gorilla (a specialist model trained on APIBench).
- DFSDT (Depth-First Search Decision Tree) significantly outperforms ReACT baselines in pass rate by expanding the search space and enabling backtracking.
Breakthrough Assessment
9/10
This is a major contribution to open-source tool use. It moves beyond toy examples to 16k+ real APIs, provides a scalable data generation pipeline (DFSDT), and includes a rigorous evaluation framework. It effectively closes the gap between LLaMA and ChatGPT for tool use.