📝 Paper Summary
Code Generation
Tool-use post-training
ToolCoder fine-tunes code generation models to autonomously trigger API search tools and integrate retrieval results into code, bridging the gap between natural language requirements and specific API usage.
Core Problem
Large code generation models often hallucinate non-existent APIs or misuse existing ones, particularly when dealing with lesser-known or private libraries not present in their training data.
Why it matters:
- Models like CodeGen generate incorrect APIs (e.g., more than 26% error rate on Numpy/Pandas) which breaks code functionality
- Industrial applications rely on private libraries that pre-trained models have never seen (error rates >90%), making standard models useless for internal tools
- Hallucinating APIs creates security and reliability risks in automated software development
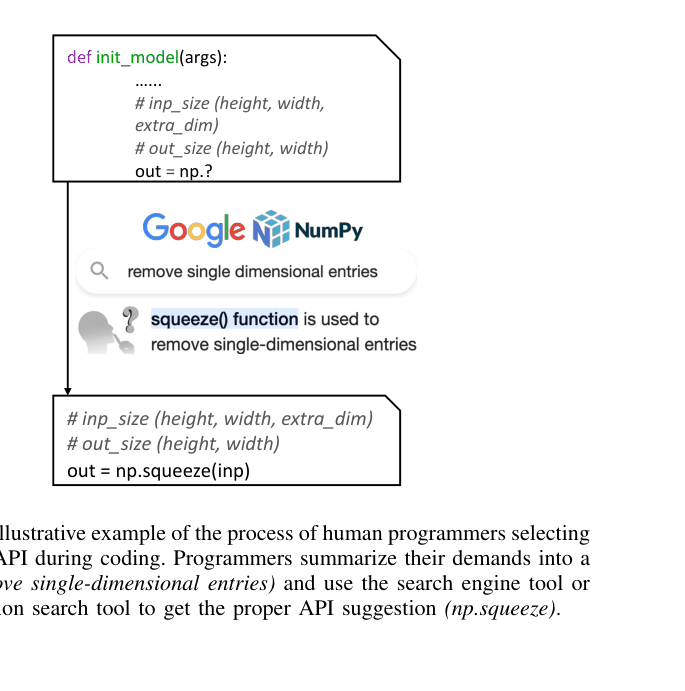
Concrete Example:
When asked to 'remove single-dimensional entries' using Numpy, a standard model might hallucinate `a.count(2)` (which doesn't exist). ToolCoder generates a search query `APISearch(remove single-dimensional entries)`, retrieves `np.squeeze` from documentation, and generates the correct code `np.squeeze(inp)`.
Key Novelty
ToolCoder (Tool-Augmented Code Generation)
- Teaches models to 'pause and search' by inserting a special token sequence `<API>APISearch(query)->answer</API>` into the generation stream
- Uses ChatGPT to automatically annotate standard code datasets with these tool-use traces, creating a training set without expensive human labeling
- Integrates two types of tools: online search engines for public libraries and BM25 documentation retrieval for private libraries
Architecture
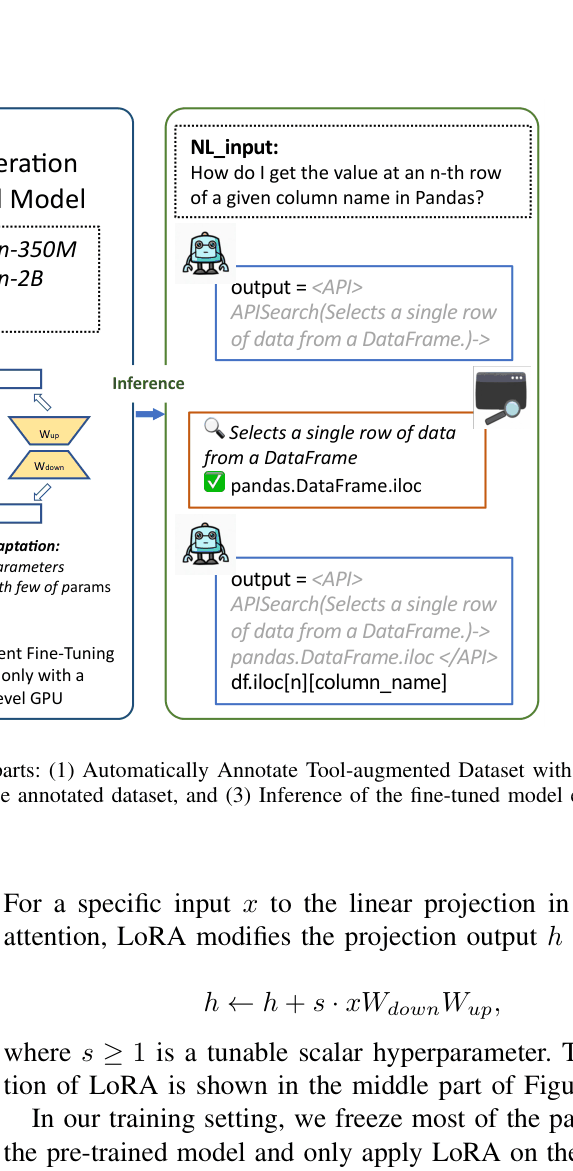
The complete pipeline of ToolCoder, from data annotation to fine-tuning and inference.
Evaluation Highlights
- Outperforms state-of-the-art API-oriented baselines by at least 10.11% on pass@1 for NumpyEval
- Achieves comparable performance to GPT-3.5 on public benchmarks despite being significantly smaller (350M/2B parameters vs. 175B+)
- Demonstrates strong generalization on private libraries (MonkeyEval, BeatNumEval), improving average pass@1 by at least 6.21% across all benchmarks compared to baselines
Breakthrough Assessment
8/10
Simple yet highly effective method for solving the 'private library' problem in code generation. The automated annotation strategy using ChatGPT is a practical contribution that lowers the barrier for tool-use training.