📝 Paper Summary
Multi-call tool use with fixed plan
Tool-use post-training
Augmented Language Models
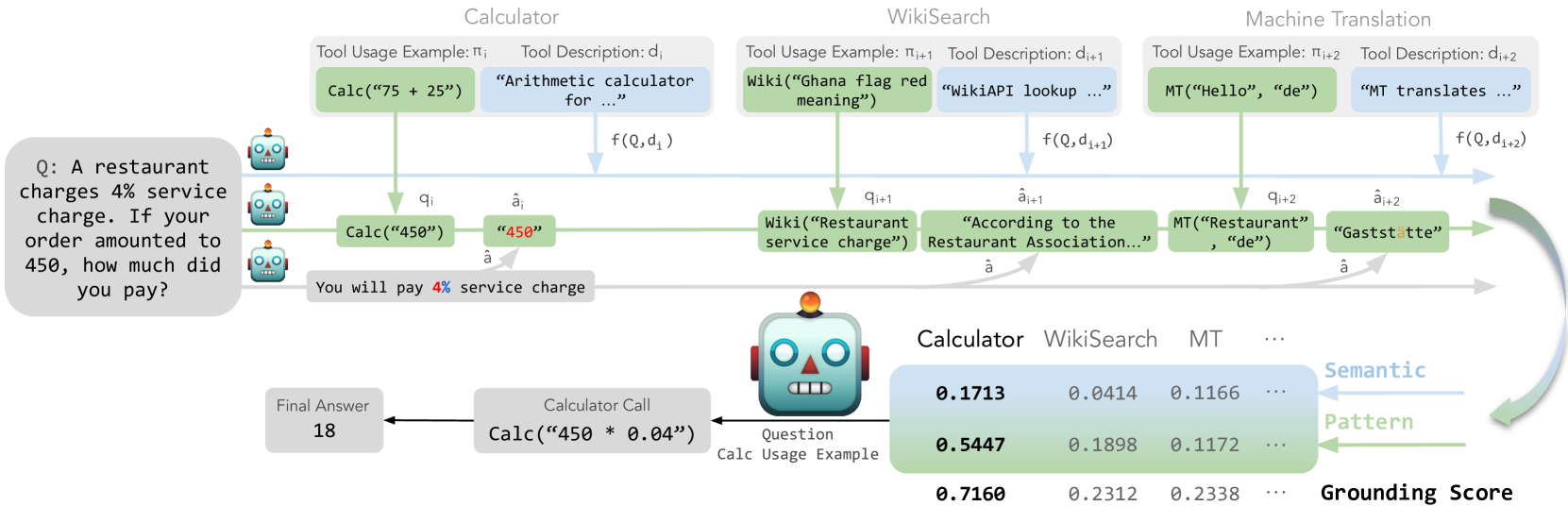
GEAR improves tool-augmented language models by offloading tool selection to small models using semantic and pattern-based matching, reserving large models only for final execution.
Core Problem
Existing tool-augmented models rely on expensive LLM calls and task-specific demonstrations for tool selection, limiting scalability and generalizability to new tools.
Why it matters:
- Current in-context learning approaches require many LLM calls, making them computationally expensive and slow
- Fine-tuning approaches (like Toolformer) cannot generalize to new tools without retraining
- Over-reliance on task-specific demonstrations restricts models from handling novel tasks that require unseen tools
Concrete Example:
When asking 'What is 100*4?', a semantic-only matcher might confuse a Calculator tool with a Math QA tool. GEAR uses a 'pattern score' to see that the Calculator outputs '400' (matching a preliminary guess) while the QA tool outputs text, correctly selecting the Calculator.
Key Novelty
Two-stage Decoupled Tool Grounding (GEAR)
- Decouples tool selection (grounding) from execution: Small Language Models (SLMs) handle selection, while Large Language Models (LLMs) handle execution
- Introduces a 'grounding score' combining semantic similarity (query vs. tool description) and pattern similarity (preliminary answer vs. tool output format)
Architecture
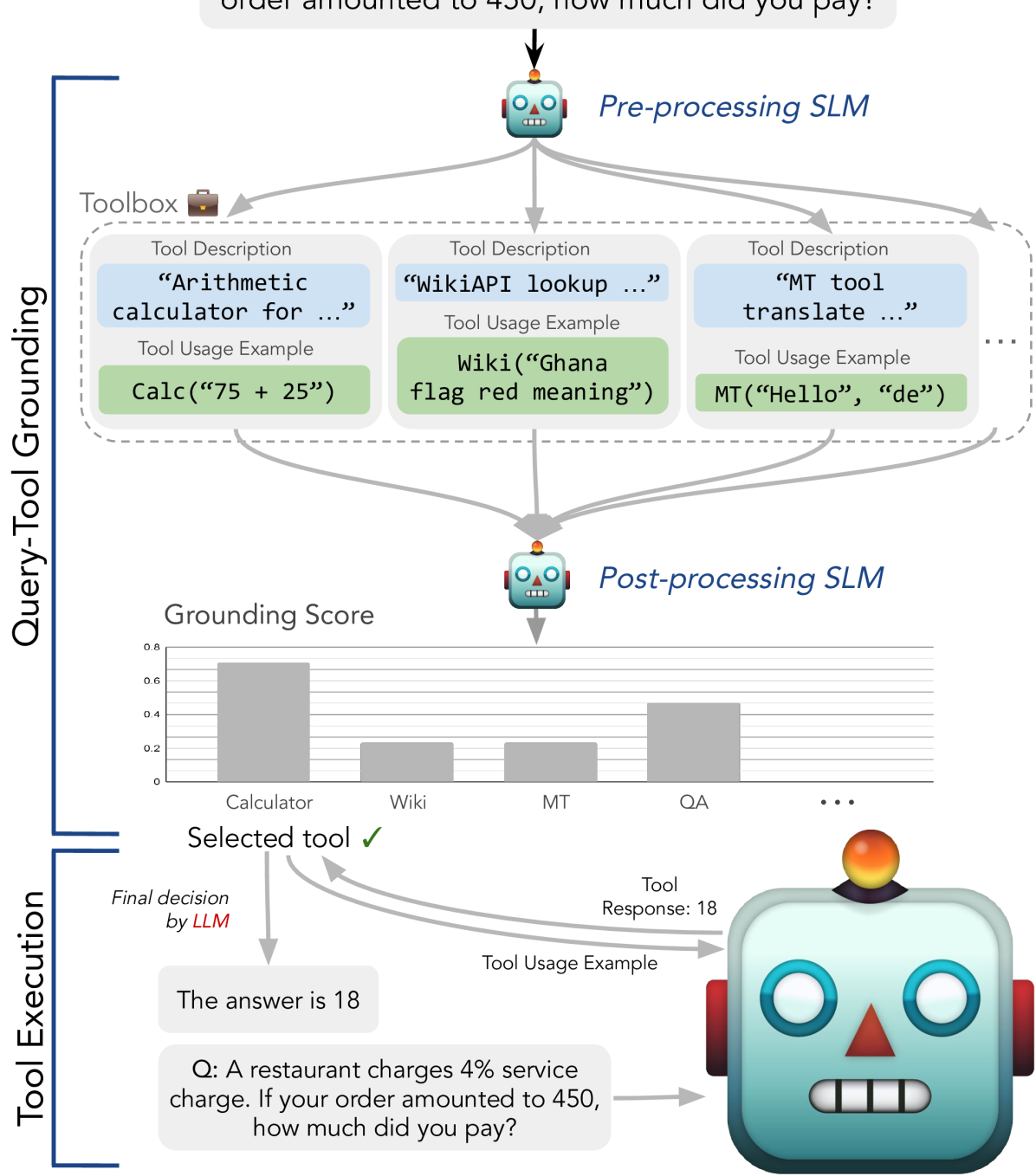
The GEAR framework pipeline showing the interaction between User, SLM, Tool Library, and LLM.
Evaluation Highlights
- GEAR with GPT-J (6B) outperforms Toolformer by +5.7% accuracy on mathematics tasks despite using a smaller model and no fine-tuning
- Reduces computational cost (FLOPS) by 4x compared to ART while achieving higher accuracy
- Achieves higher precision in tool grounding compared to strategies relying solely on LLM prompting
Breakthrough Assessment
7/10
Strong practical contribution for efficiency and generalization. The dual-scoring mechanism (semantic + pattern) is a clever, lightweight heuristic that effectively decouples reasoning from tool selection.