📝 Paper Summary
LLM Data Governance
Dataset Auditing
The ROOTS Search Tool provides a fuzzy and exact search engine over the 1.6TB multilingual corpus used to train BLOOM, enabling qualitative auditing of training data while respecting data governance.
Core Problem
Large language models are trained on massive web-scale corpora (like the 1.6TB ROOTS corpus) that are difficult to inspect, leading to unknown quality issues, biases, and PII leakage.
Why it matters:
- Without inspection tools, researchers cannot determine if model outputs are memorized or generalized
- Undocumented training data makes it impossible to verify if data was ethically sourced or if it contains harmful social stereotypes
- Traditional corpus linguistics tools cannot handle the scale of modern LLM training sets (e.g., 1.6TB)
Concrete Example:
Users checking if BLOOM 'hallucinated' a fact cannot easily verify if the falsehood existed in the training data. For instance, the tool revealed 5 snippets in OSCAR falsely claiming Barack Obama was born in Kenya, explaining potential model errors.
Key Novelty
Web-Scale Corpus Search for LLM Transparency
- First search engine dedicated to the full training corpus of a specific Large Language Model (BLOOM), handling 1.6TB of multilingual text
- Implements a 'governance-first' search interface that displays only short 128-word snippets and obfuscates PII (Personally Identifiable Information) to prevent data reconstruction while allowing audit
Architecture
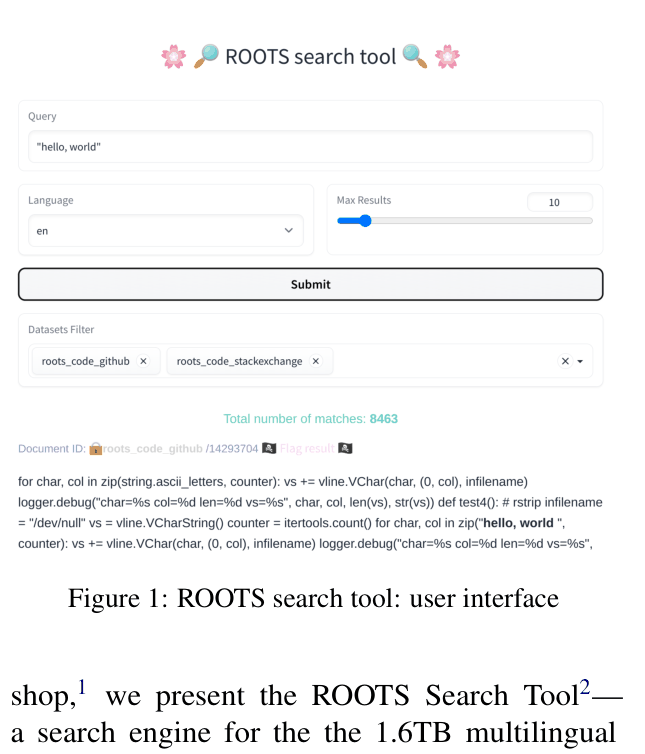
Screenshot of the user interface showing a search for 'gmail.com' with PII redaction active
Evaluation Highlights
- Successfully indexed 1.6TB of data across 46 natural languages and 13 programming languages
- Enabled detection of PII leakage in the OSCAR dataset (e.g., unredacted names) despite prior cleaning efforts
- Revealed that BLOOM failed to memorize the 'Macbeth' quote despite having access to at least 7 sources, while it memorized 'Hamlet' (47+ sources)
Breakthrough Assessment
8/10
Significant step for AI transparency. While the technology (BM25/Suffix Arrays) is standard, applying it to open up a 1.6TB training corpus for public audit is a major governance breakthrough.