📝 Paper Summary
Tool-use post-training
RL-based tool learning
Trice is a two-stage training framework that teaches language models to selectively use tools only when necessary by leveraging reinforcement learning on execution feedback.
Core Problem
Existing tool learning methods often force models to use tools indiscriminately, even for simple tasks the model could solve itself.
Why it matters:
- Using tools for simple problems can propagate errors (e.g., wrong tool selection or inputs) rather than helping
- Current approaches lack the ability to discern *when* a tool is actually necessary versus when the model's internal knowledge suffices
- Excessive reliance on tools increases computational cost and latency without guaranteeing better performance
Concrete Example:
For a simple question like 'What is 2+2?', a model forced to use a calculator might generate a malformed API call or misinterpret the output, failing a task it could have answered directly. Trice teaches the model to answer '4' directly but invoke a calculator for '345 * 921'.
Key Novelty
Tool Learning with Execution Feedback (Trice)
- Uses a two-stage process: first cloning behavior from a dataset where tool use is only labeled for hard instances (where the base model fails)
- Then uses Reinforcement Learning with Execution Feedback (RLEF) to align the model with responses that correctly decide whether to use a tool or not based on actual success
Architecture
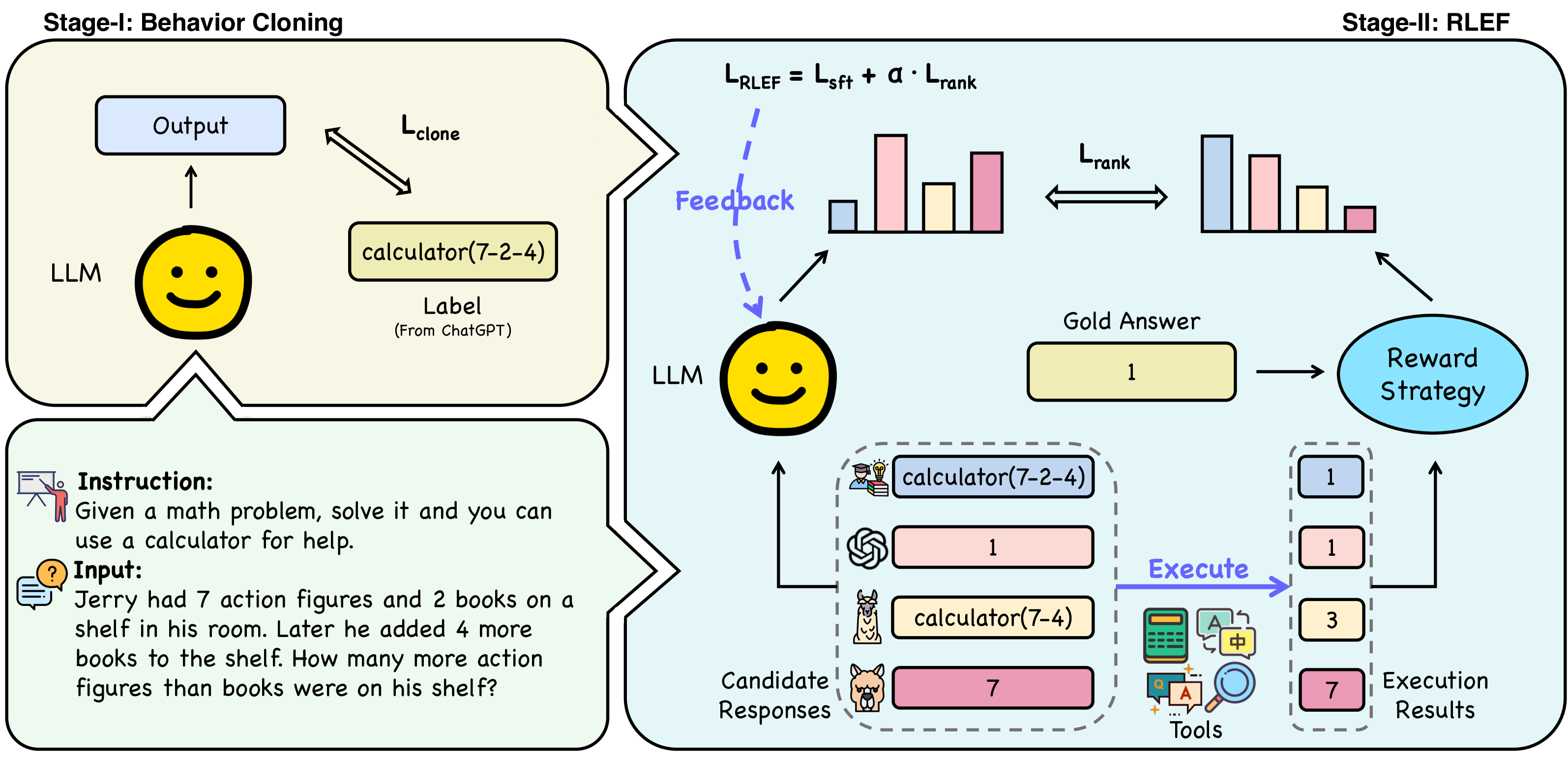
The two-stage training framework of Trice.
Evaluation Highlights
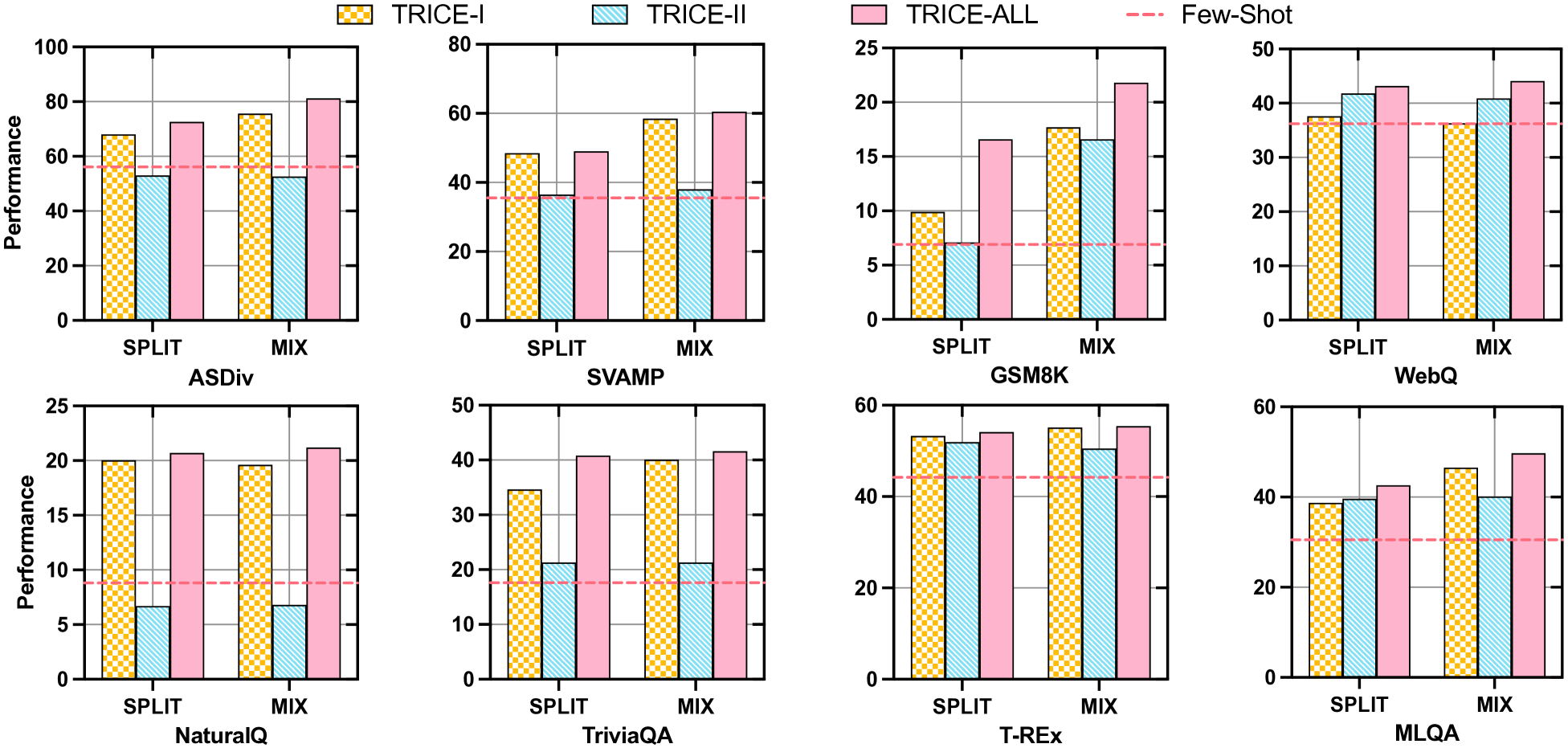
- Outperforms baselines (including ChatGPT and Vicuna) on 4 tasks across 8 datasets, showing better selective tool usage
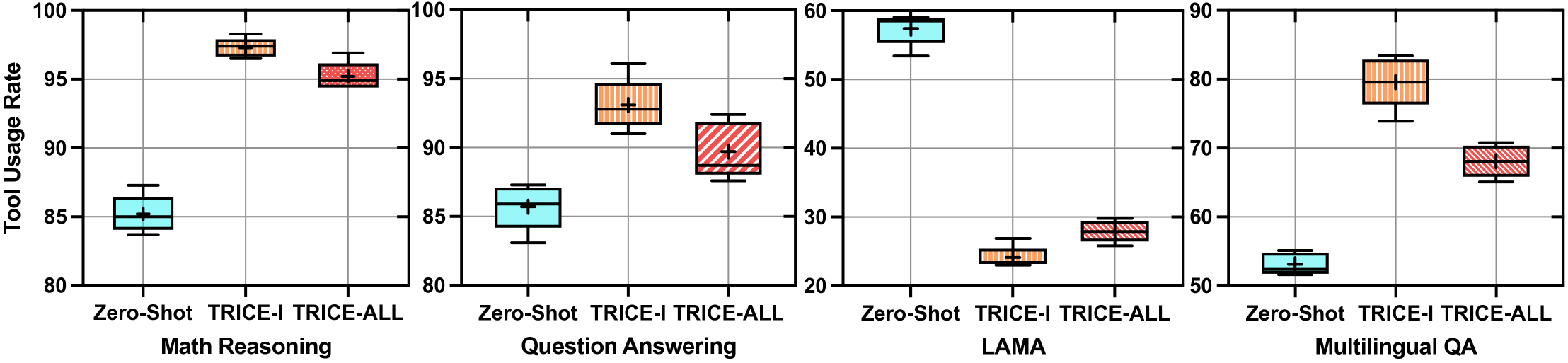
- Reduces tool usage rate on easy instances while maintaining high performance on hard instances
- Achieves higher accuracy than 100% tool-use baselines, proving that selective usage prevents error propagation
Breakthrough Assessment
7/10
Addresses a critical and often overlooked problem in tool learning (over-reliance). The methodology is sound and the results demonstrate clear benefits of selective execution.