📝 Paper Summary
Multi-call tool use with fixed plan
Retrieval
A two-stage tool retrieval system that replaces description-based embeddings with usage-based embeddings (Tool2Vec) and refines candidates using a multi-label classification model to improve LLM function calling.
Core Problem
LLMs cannot efficiently handle thousands of tools due to context window limits, and existing dense retrieval methods based on tool descriptions suffer from a semantic gap between user queries and technical descriptions.
Why it matters:
- Passing thousands of function descriptions into an LLM's context window is often infeasible or prohibitively expensive
- Existing retrieval methods rely on tool descriptions, which often fail to capture the nuances of how a user actually queries for a tool (the semantic gap)
- Latency in real-time applications makes heavy reasoning-based retrieval (using an LLM to select tools) impractical
Concrete Example:
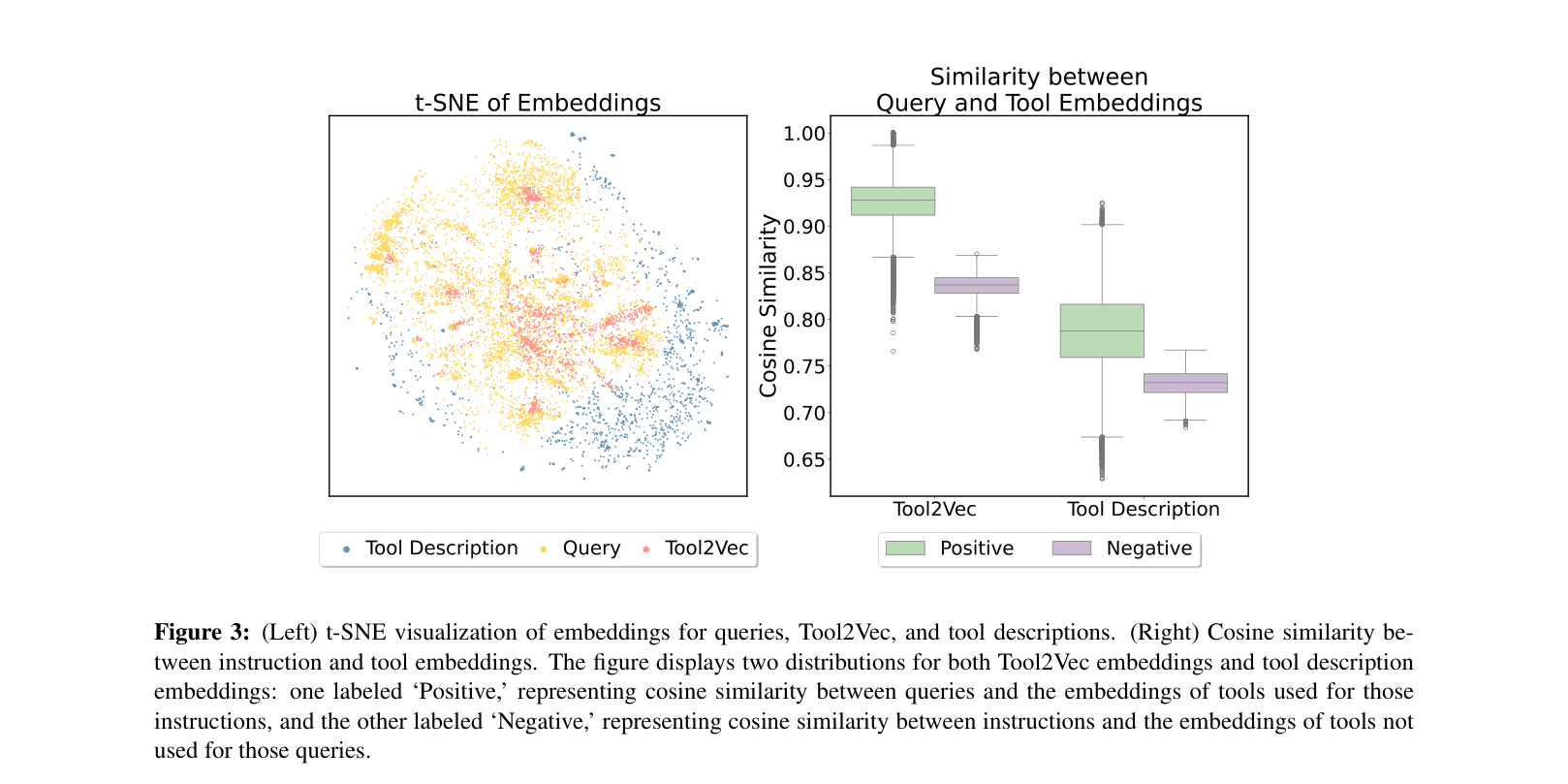
A user asks 'What is Anna's email address?'. A description-based retriever might fail to link this to a tool named 'find_email_address' because the description 'returns the email address for the given name' is semantically distant from the query. Tool2Vec bridges this by embedding the example query itself as the tool's representation.
Key Novelty
Tool2Vec + ToolRefiner (Two-Stage Usage-Driven Retrieval)
- Replaces tool description embeddings with 'usage-driven' embeddings (Tool2Vec) derived from averaging embeddings of example user queries associated with each tool
- Implements a retrieve-then-refine pipeline where a fast initial retriever prunes the search space, followed by a fine-tuned classifier (ToolRefiner) that considers tool-query interactions
Architecture
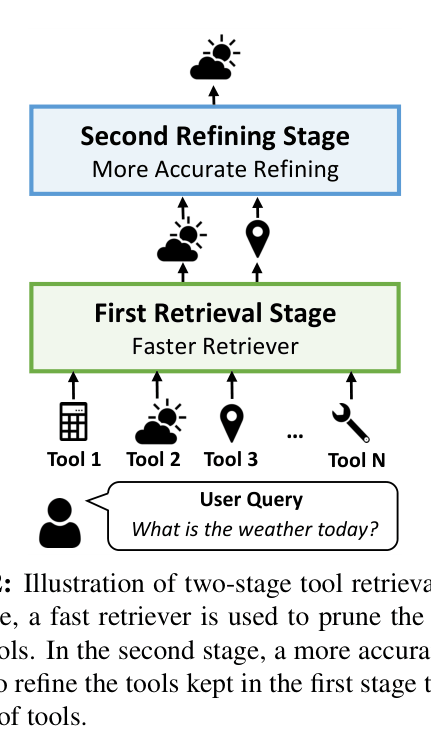
The two-stage retrieval pipeline. Stage 1 (Fast Retriever) prunes tools using Tool2Vec or MLC. Stage 2 (ToolRefiner) refines the set using a fine-tuned encoder that takes the query and Tool2Vec embeddings as input.
Evaluation Highlights
- +27.28 Recall@3 improvement on the ToolBench dataset compared to the standard description-based ToolBench retriever
- +30.5 Recall@3 improvement on the newly created ToolBank dataset compared to description-based baselines
- Achieves higher recall than the COLT retriever baseline on ToolBench I2 and I3 subsets when using ToolRefiner + MLC
Breakthrough Assessment
7/10
Significant performance gains over standard description-based retrieval by shifting to usage-based embeddings. Practical two-stage architecture. Limited by reliance on having query data for every tool.