📝 Paper Summary
Tool use / Tool learning
Memory-augmented exploration
STE enables LLMs to master tools by simulating trial-and-error interactions, using memory to refine exploration, and training on the resulting successful trajectories.
Core Problem
Existing LLMs, including GPT-4 and tool-finetuned models, exhibit low accuracy (30-60%) when using tools, failing to reliably master the specific tools they are trained for.
Why it matters:
- Current methods focus on tool coverage or flexibility rather than the reliability/accuracy needed for production deployment
- Inaccurate tool use in consequential domains (e.g., financial transactions) undermines user trust and causes harmful outcomes
- Standard fine-tuning lacks the trial-and-error feedback loop essential for mastering complex cognitive tasks like tool use
Concrete Example:
When using a new API, a standard LLM might hallucinate arguments or fail syntax checks. With STE, the model 'imagines' a task, attempts it, encounters the error, corrects it via self-reflection, and stores the corrected trajectory for future training.
Key Novelty
Simulated Trial and Error (STE)
- Biologically inspired framework where the LLM 'imagines' tasks and learns through an iterative execute-observe-refine loop, rather than just reading documentation
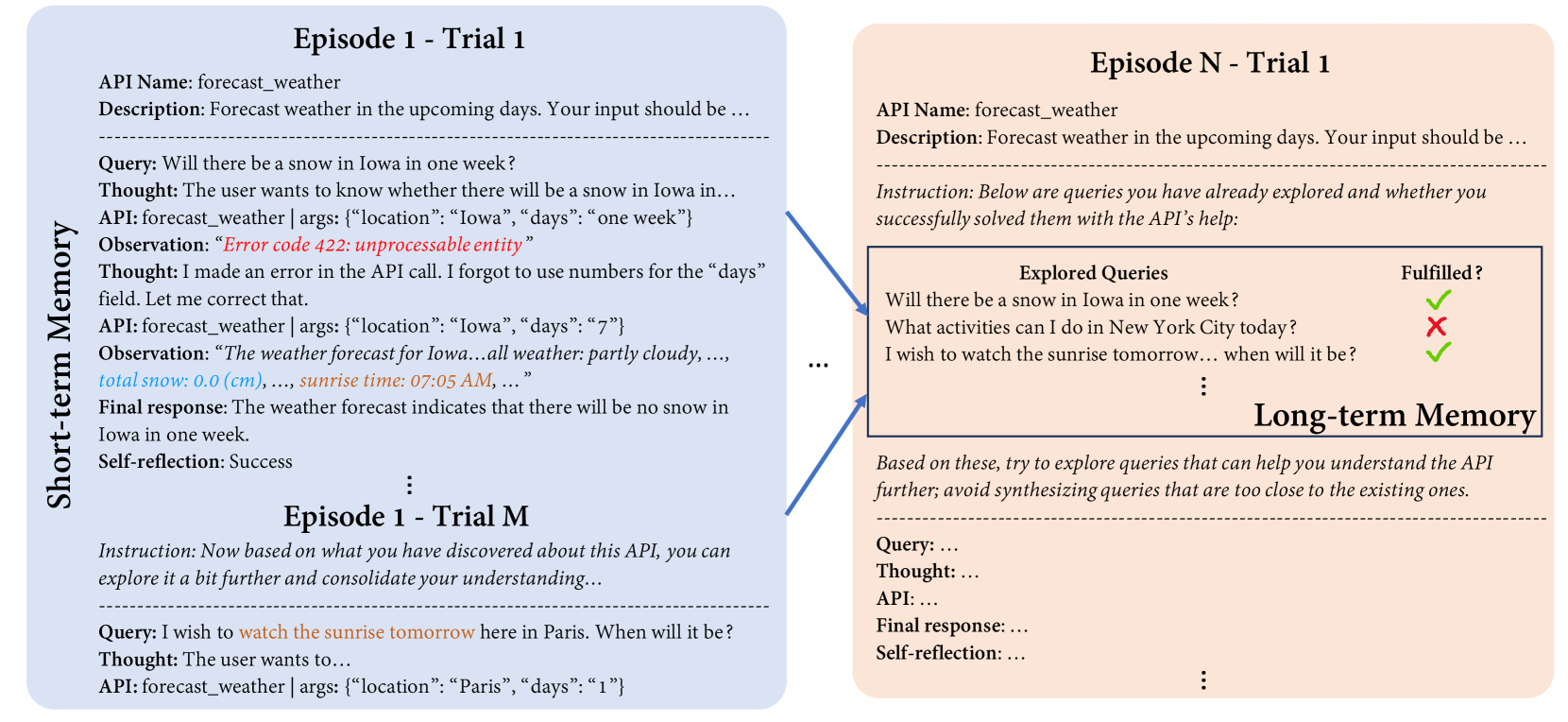
- Short-term memory stores recent trajectories to deepen exploration within an episode, while long-term memory distills past successes to broaden exploration across episodes
- Decouples exploration (using a strong teacher model like ChatGPT) from exploitation (fine-tuning a smaller student model on curated trajectories)
Architecture
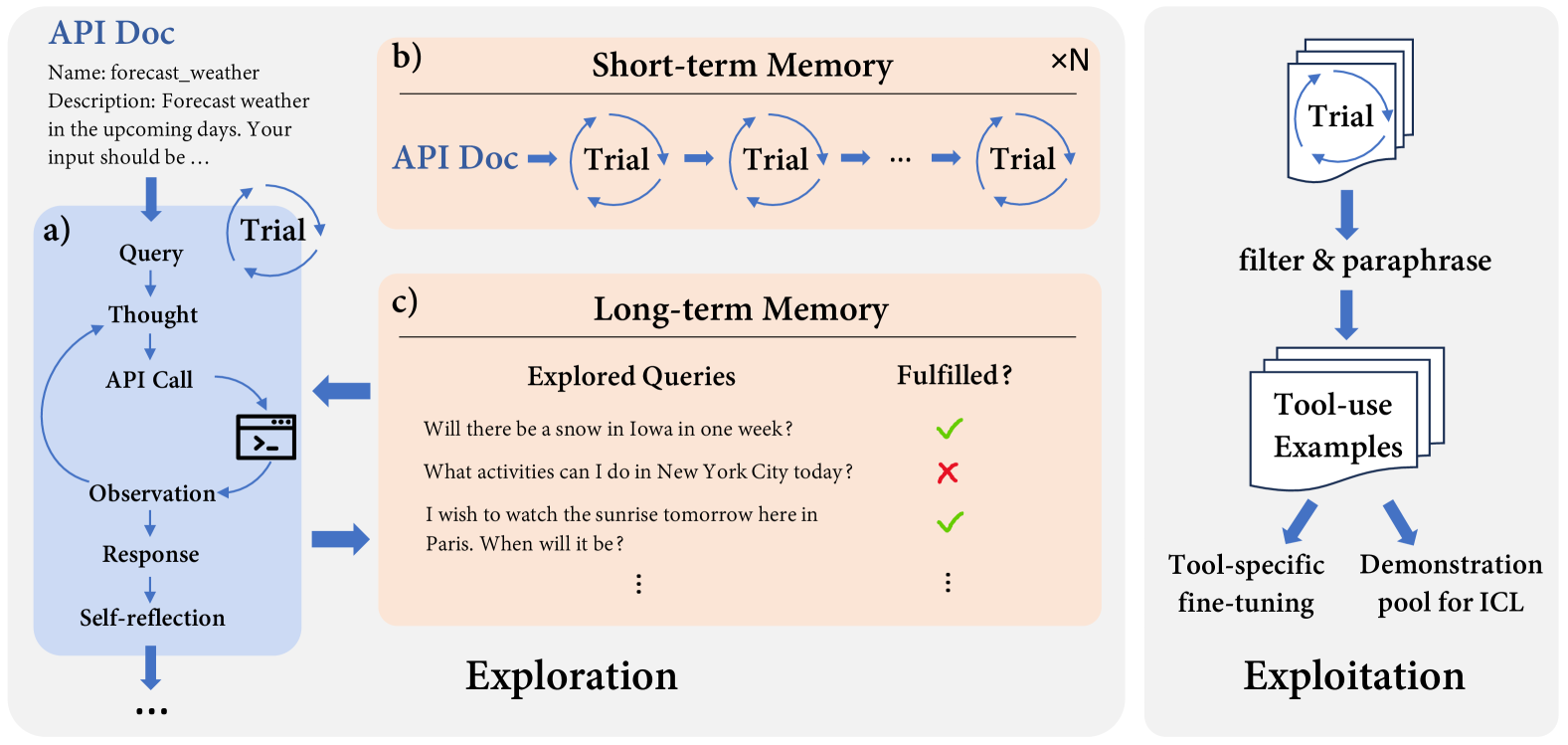
The conceptual framework of Simulated Trial and Error (STE), contrasting Exploration and Exploitation phases.
Evaluation Highlights
- Mistral-Instruct-7B fine-tuned with STE achieves 76.8% tool-use correctness, outperforming GPT-4 (60.8%)
- STE provides a massive 46.7% absolute improvement over the base Mistral-Instruct-7B model
- ToolLLaMA-v2, a specialized SOTA tool-use model, only achieves 37.3% accuracy, significantly underperforming the STE-augmented models
Breakthrough Assessment
8/10
Demonstrates a highly effective methodology for tool mastery that beats GPT-4 with a 7B model. The biologically inspired memory/trial-and-error approach is intuitive and yields large gains.