📊 Experiments & Results
Evaluation Setup
Reward Model accuracy evaluation and Downstream Tool-Use enhancement via Rejection Sampling
Benchmarks:
- FC-RewardBench (Reward Model Evaluation (Pairwise Comparison)) [New]
- Berkeley Function Calling Leaderboard (BFCL) v3 (Tool Use / Function Calling)
- API-Bank (Tool Use / Dialogue)
- ToolAlpaca (Tool Use)
- NexusRaven API Evaluation (Tool Use)
Metrics:
- Accuracy (pairwise preference)
- Full Sequence Matching (correct tool name + args)
- AST-based Accuracy (Abstract Syntax Tree matching for BFCL)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Best-of-N (N=32) experiments show massive gains for smaller models using ToolRM selection, with diminishing returns for larger models. | ||||
| Average across 5 benchmarks (API-Bank, ToolAlpaca, etc.) | Accuracy | 39.5 | 64.4 | +24.9 |
| Average across 5 benchmarks (API-Bank, ToolAlpaca, etc.) | Accuracy | 64.9 | 70.5 | +5.6 |
| BFCL v3 | Overall Accuracy | 59.20 | 64.50 | +5.30 |
| FC-RewardBench evaluation demonstrates ToolRM's superior ability to identify correct tool calls compared to general-purpose baselines. | ||||
| FC-RewardBench | Accuracy | 45.0 | 88.0 | +43.0 |
Experiment Figures
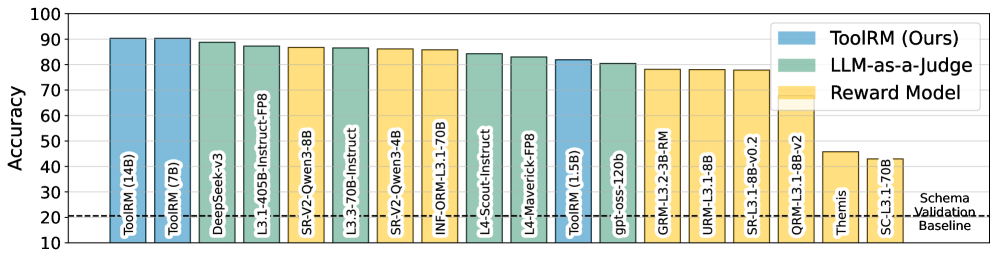
Accuracy comparison of various Reward Models and LLMs-as-Judges on the FC-RewardBench dataset.
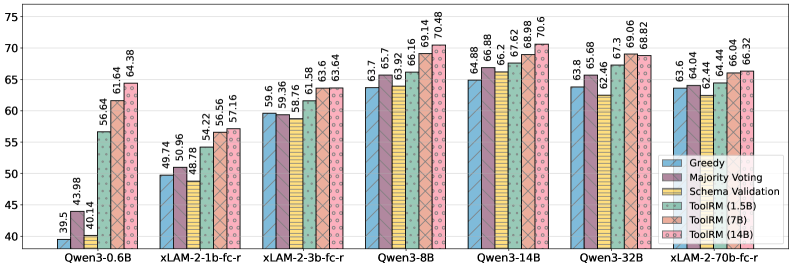
Best-of-N performance gains across 5 benchmarks for different generator models (xLAM-2 and Qwen3 series).
Main Takeaways
- Small Language Models (SLMs) benefit most from ToolRM-guided sampling, with Qwen3-0.6B matching or surpassing 70B parameter models using greedy decoding.
- General-purpose reward models and even tool-augmented RMs (like Themis) perform poorly on function-calling verification, often failing to detect subtle parameter errors.
- FC-RewardBench correlates strongly (0.84 correlation) with downstream Best-of-N performance, validating it as a reliable proxy for RM evaluation.
- Improvements diminish for very large generator models (32B+), suggesting they make fewer errors that are detectable/correctable by the reward model.