📝 Paper Summary
Tool-use post-training
Multi-call tool use with flexible plan
AutoTools enables LLMs to automatically convert raw tool documentation into verified, executable Python functions and solve tasks by generating programs, without requiring manual prompt engineering.
Core Problem
Existing tool-use methods rely on manual parsing of documentation and rigid, pre-defined templates (like JSON), which scale poorly to large toolsets and limit flexibility.
Why it matters:
- Manually crafting demonstrations for thousands of APIs requires intense domain expertise and effort, creating a bottleneck for scaling tool agents
- Fixed templates (e.g., JSON schemas) struggle to handle complex dependencies where the output of one tool must be processed before becoming the input for another
- LLMs often fail when in-context examples are missing or incomplete, limiting their ability to use new tools 'in the wild'
Concrete Example:
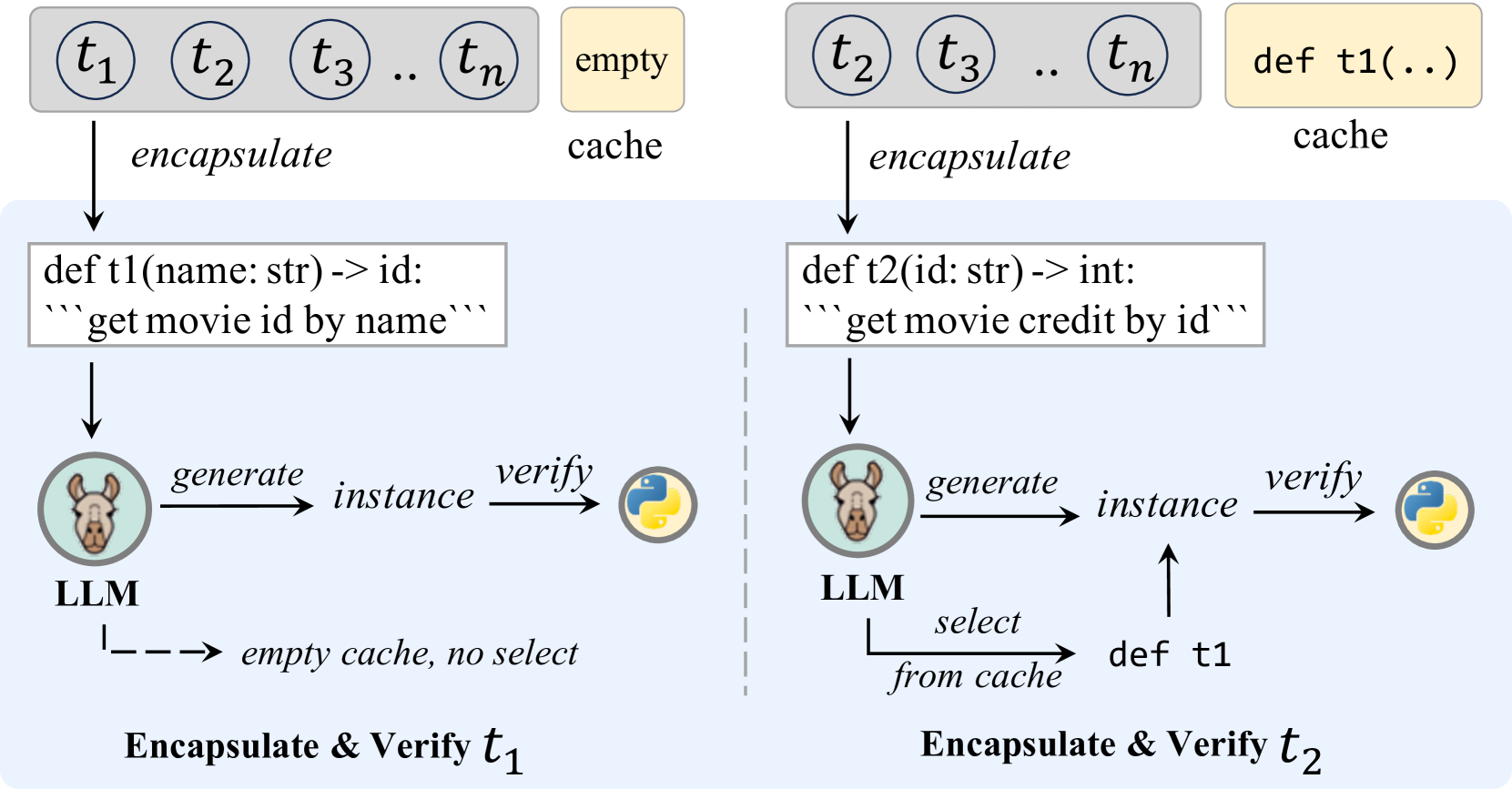
A task might require retrieving a movie's credits using a unique ID found via a search tool. Current methods struggle to pass the search output to the credit tool without explicit manual examples. AutoTools handles this by writing a Python script that stores the search result in a variable and passes it to the next function.
Key Novelty
AutoTools Framework
- Self-Encapsulation: Instead of human-written wrappers, the LLM reads raw documentation and writes its own Python function wrappers, including docstrings
- Integration Verification: The model generates its own test cases to verify these functions work, checking for runtime errors and input-output dependencies
- Tool Programming: The agent solves tasks by writing executable Python code that calls these self-generated functions, allowing for logic like loops and variable storage
Architecture
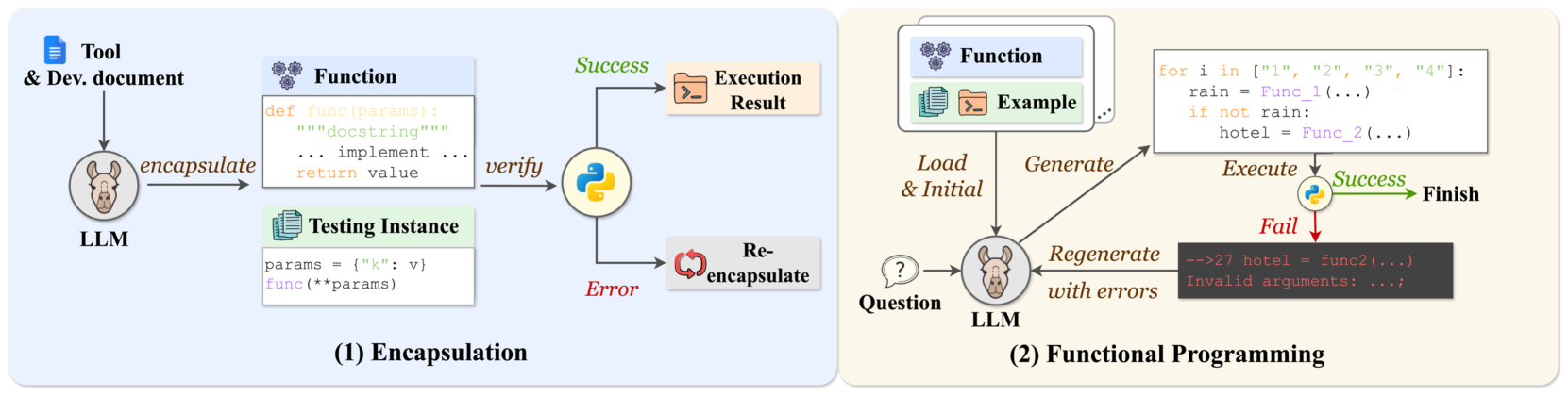
The complete AutoTools framework, split into the Tool Encapsulation stage (converting docs to functions) and the Tool Programming stage (solving queries).
Evaluation Highlights
- AutoTools with GPT-4 achieves 64.1 Pass Rate on the ToolBench benchmark, outperforming ToolLLM (using Llama-2-7B) which scored 56.8
- On the new AutoTools-Eval benchmark, the proposed AutoTools-L-13B model achieves a 57.6 Pass Rate, surpassing GPT-3.5-Turbo (51.8)
- The method is highly efficient, using significantly fewer tokens than ReAct or ToolLLM baselines while maintaining higher accuracy
Breakthrough Assessment
8/10
Significant shift from manual tool definition to fully automated encapsulation and verification. The move to programmatic interaction (Python) over JSON parsing for tool use addresses key flexibility bottlenecks.