📝 Paper Summary
Tool-augmented scientific reasoning
Agentic data synthesis
Tool retrieval
SciAgent enhances scientific reasoning by shifting LLMs from omniscient solvers to proficient tool-users, trained on a large-scale synthetic corpus of math functions and evaluated on a new multi-domain benchmark.
Core Problem
Scientific reasoning requires both specialized domain knowledge and calculation skills, but annotated data is scarce and fine-tuning models for every new domain is prohibitively expensive.
Why it matters:
- Current LLMs (even GPT-4) struggle with scientific reasoning, achieving only ~35-50% accuracy on benchmarks like SciBench and TheoremQA.
- Purely data-driven approaches require expensive expert annotation for every new scientific field.
- Existing methods lack a scalable way to teach LLMs how to use pre-existing scientific tools (functions) rather than memorizing all knowledge.
Concrete Example:
To solve a physics problem about Malus' law, a model must know the specific formula and perform precise calculations. Standard LLMs often hallucinate the formula or fail the arithmetic. SciAgent retrieves a correct Python function for Malus' law from a toolset and executes it to get the exact answer.
Key Novelty
MathFunc Corpus & SciAgent Framework
- Constructs 'MathFunc', a synthetic training corpus where GPT-4 generates reusable functions, plans, and tool-augmented solutions for math problems.
- disentangles tool creation from solution generation: uses a cross-retrieval strategy to fetch generalized functions from other problems, preventing the model from learning ad-hoc, problem-specific shortcuts.
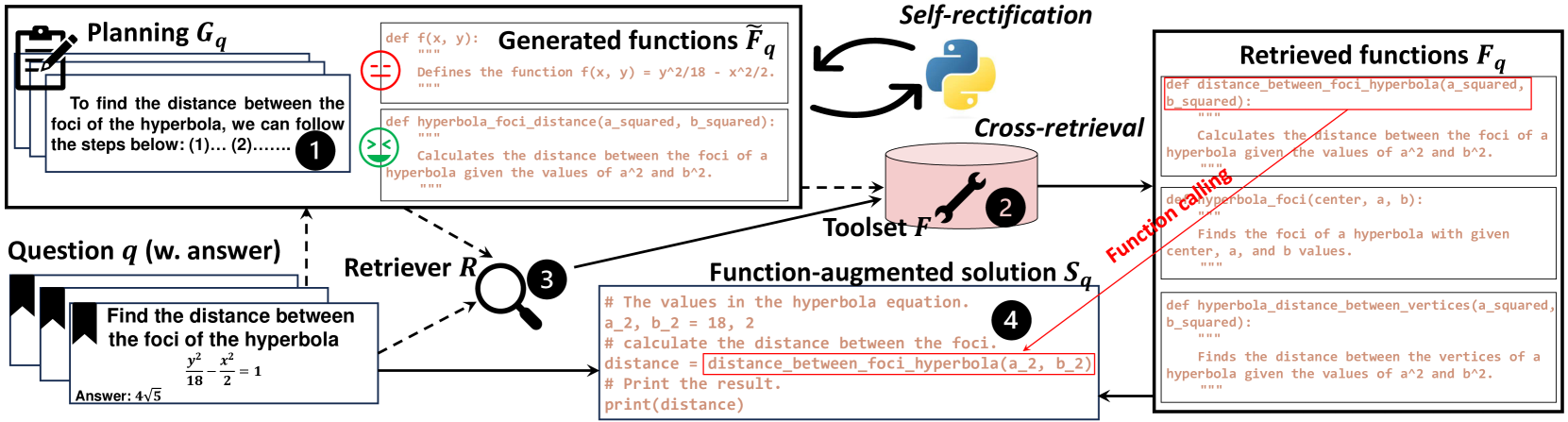
- Trains a four-stage agent (Planning, Retrieval, Action, Execution) that explicitly plans before retrieving tools, improving relevance and reasoning structure.
Architecture

The inference pipeline of SciAgent.
Evaluation Highlights
- +13.4% absolute accuracy for SciAgent-Mistral-7B over comparable open-source models (e.g., Chameleon, ToolAlpaca) on the new SciToolBench.
- SciAgent-DeepMath-7B outperforms ChatGPT (gpt-3.5-turbo) by a large margin on SciToolBench.
- SciAgent-DeepMath-7B achieves 46.61% on SciToolBench, surpassing LLaMA-2-70B (26.05%) significantly despite being 10x smaller.
Breakthrough Assessment
7/10
Strong contribution in synthetic data generation for tool use and a solid new benchmark. The performance gains are significant for 7B models, though reliance on GPT-4 for data generation is a standard but limiting factor.