📝 Paper Summary
Agentic AI
Tool Learning
Evaluation Benchmarks
GTA is a benchmark evaluating tool agents on human-written, multimodal tasks where tool-use steps are implicit, revealing that current LLMs struggle significantly with real-world planning.
Core Problem
Existing tool-use benchmarks rely on AI-generated queries with explicit step-by-step instructions, dummy tools, and text-only contexts, which fail to test an agent's ability to reason and plan in complex real-world scenarios.
Why it matters:
- AI-generated queries often explicitly hint at tool usage (e.g., 'Use the search tool to find...'), bypassing the critical reasoning phase required in reality.
- Real-world user interaction is multimodal (images, screenshots, spatial scenes), but most benchmarks are text-only.
- Simulated tools in prior benchmarks only evaluate isolated steps, failing to test end-to-end execution reliability.
Concrete Example:
A typical benchmark might ask 'Use Google Search to find the 2024 QS ranking of Tsinghua,' making the plan obvious. GTA asks 'What is the 2024 QS ranking of Tsinghua?' (implicit tool need) accompanied by a relevant screenshot, requiring the agent to deduce the need for search and visual interpretation.
Key Novelty
Realistic Implicit Tool-Use Evaluation (GTA)
- Constructs queries using human design rather than AI generation to ensure goals are clear but execution steps are implicit, forcing agents to plan rather than just follow instructions.
- Integrates 14 real deployed tools across perception, operation, logic, and creativity categories, executing actual code rather than simulating outputs.
- Incorporates authentic multimodal inputs (images, code snippets, tables) as essential context for the queries.
Architecture
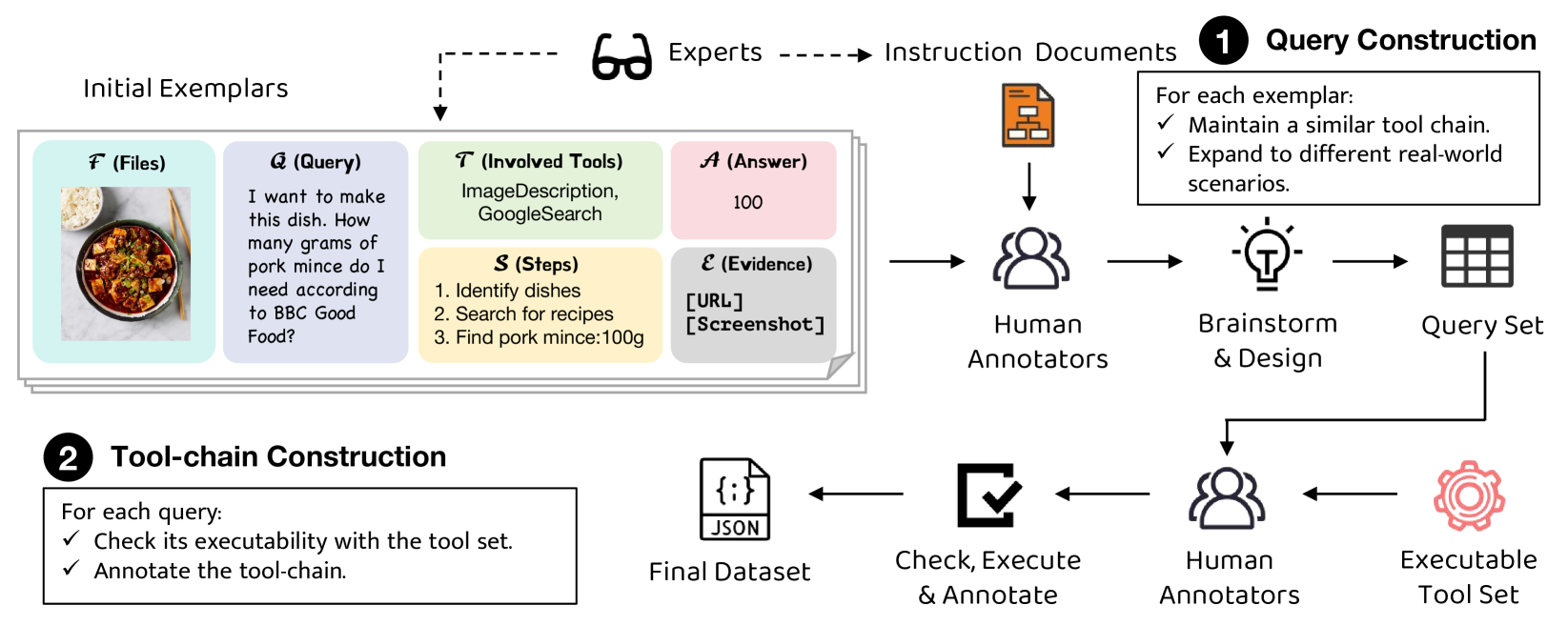
The dataset construction pipeline for GTA.
Evaluation Highlights
- GPT-4 achieves a success rate of less than 50% on GTA tasks, highlighting the difficulty of real-world implicit planning.
- Most mainstream LLMs achieve a success rate below 25%, indicating a significant gap between current capabilities and general agent requirements.
Breakthrough Assessment
8/10
Significantly raises the bar for agent evaluation by moving away from 'toy' synthetic tasks to implicit, executable, multimodal real-world scenarios that expose actual model failures.
