📝 Paper Summary
Tool-use post-training
Multi-call tool use with fixed plan
ToolAlpaca creates a diverse tool-use corpus via multi-agent simulation to enable compact language models to generalize to unseen tools without specific training.
Core Problem
Compact language models lack generalized tool-use abilities and require specific training for new tools, unlike extremely large models like GPT-4.
Why it matters:
- Existing diversified tool-use corpora are unavailable due to the difficulty of collecting diverse APIs and the manual effort required for multi-turn interactions
- Compact models (e.g., Vicuna) cannot currently generalize to unseen tools, limiting their utility in embodied intelligence compared to proprietary giants like GPT-4
Concrete Example:
Without fine-tuning on ToolAlpaca, a Vicuna-7B model achieves only a 7.9% human acceptance rate on real-world APIs, failing to structure parameters or select correct actions, whereas GPT-3.5 achieves 75.4%.
Key Novelty
Multi-agent Simulation Framework for Tool Learning
- Constructs a toolset by scraping API introductions and using an LLM to hallucinate comprehensive documentation and OpenAPI specifications
- Simulates tool-use scenarios using three agents (User, Assistant, Tool Executor) to generate valid multi-turn interaction data without human intervention
Architecture
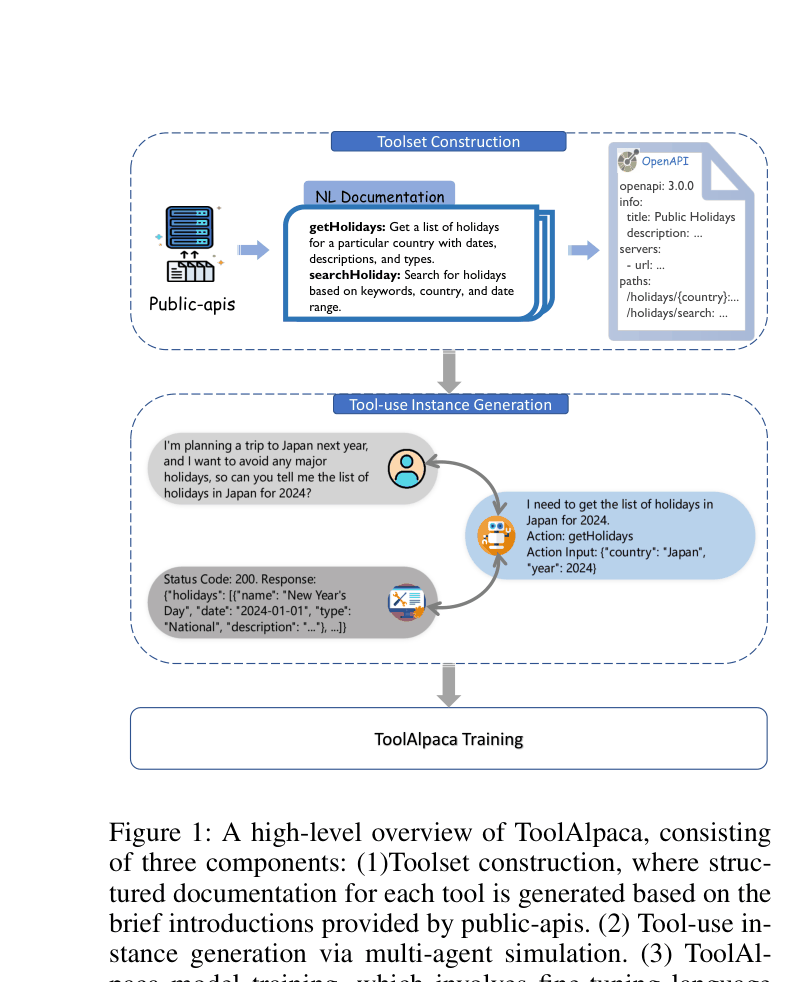
Overview of the ToolAlpaca framework, including toolset construction, instance generation, and training
Evaluation Highlights
- ToolAlpaca-13B achieves parity with GPT-3.5 on unseen simulated tools (75.0 vs 75.0 overall score)
- Generalized performance on real-world APIs jumps from 12.3 (Vicuna-13B) to 61.4 (ToolAlpaca-13B) overall score
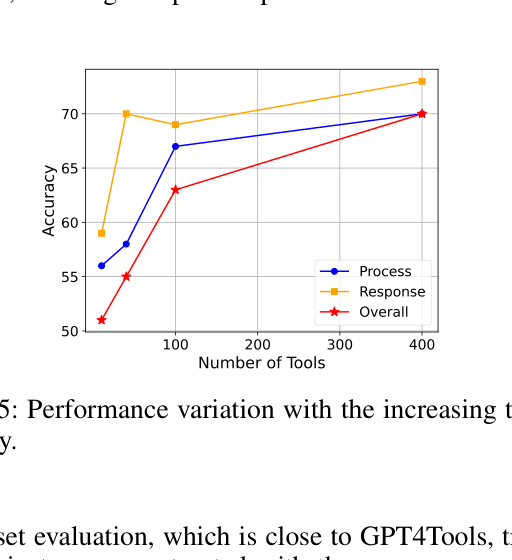
- Achieves 83.7% success rate on out-of-distribution multi-modal tools (GPT4Tools test set) using only 3.9k training cases
Breakthrough Assessment
8/10
Demonstrates that compact models can learn generalized tool use from a small, synthetic dataset (3000 cases), challenging the assumption that only massive models possess this capability.