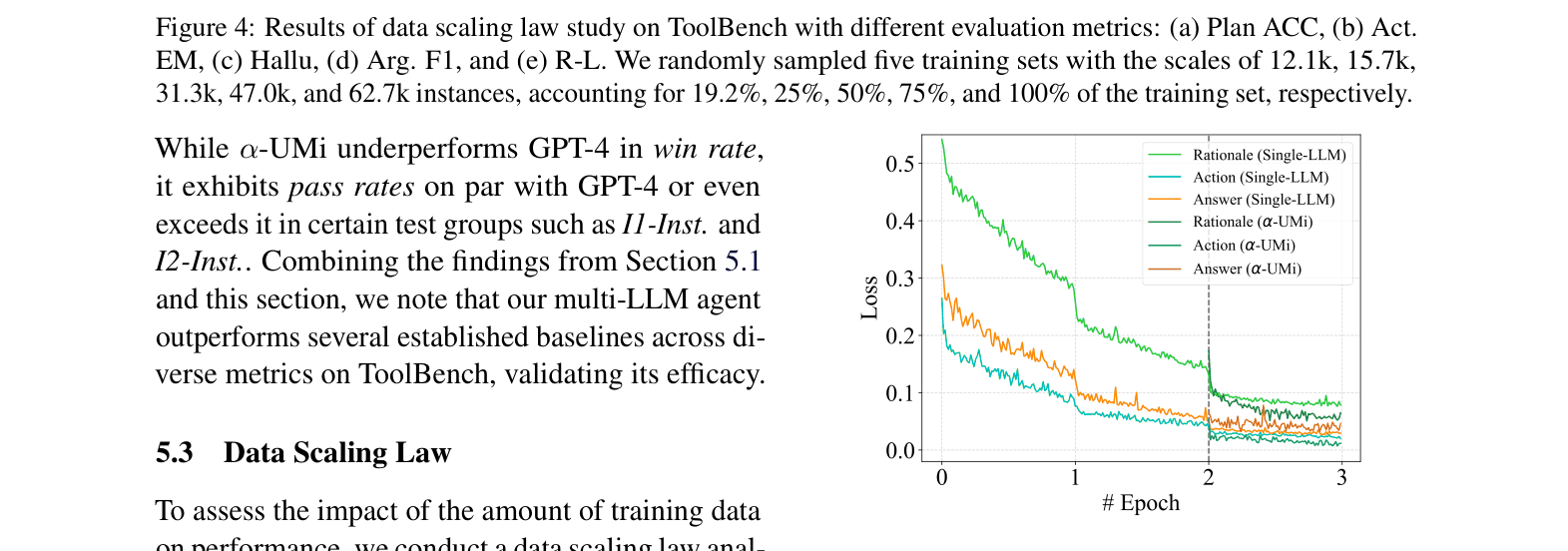
📝 Paper Summary
Multi-call tool use with flexible plan
Multi-agent
α-UMi decomposes a tool-learning agent into three specialized small LLMs (planner, caller, summarizer) fine-tuned via a global-to-local progressive strategy, outperforming single-LLM approaches.
Core Problem
Single small LLMs (e.g., 7B) struggle to simultaneously master diverse tool-use capabilities like reasoning, precise API formatting, and summarization due to limited model capacity.
Why it matters:
- Small open-source models (like LLaMA-7B) significantly lag behind closed-source giants (GPT-4) in complex agent tasks
- Training a single model for all agent sub-tasks creates interference, where improving reasoning might degrade API syntax compliance
- Real-world tool updates require expensive retraining of the entire monolithic model rather than just the relevant component
Concrete Example:
In a complex task requiring multiple API calls (e.g., searching for a video and then getting its details), a single 13B model might get stuck in a loop calling a broken API or fail to format the request correctly, whereas the specialized planner in α-UMi detects the failure and redirects the caller to an alternative tool.
Key Novelty
α-UMi (Multi-LLM Agent Framework)
- Decompose the monolithic agent role into three specialized roles: a 'Planner' for reasoning/direction, a 'Caller' for syntax-perfect tool invocation, and a 'Summarizer' for user response generation
- Global-to-Local Progressive Fine-Tuning (GLPFT): First train a single backbone on all tasks to establish shared understanding, then spawn three copies and fine-tune each exclusively on its specific sub-task to maximize specialization
Architecture
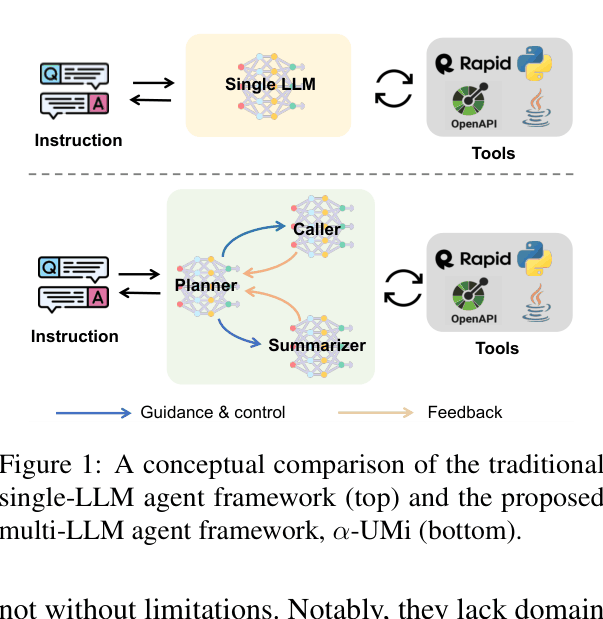
Conceptual comparison between Single-LLM agent and α-UMi Multi-LLM agent
Evaluation Highlights
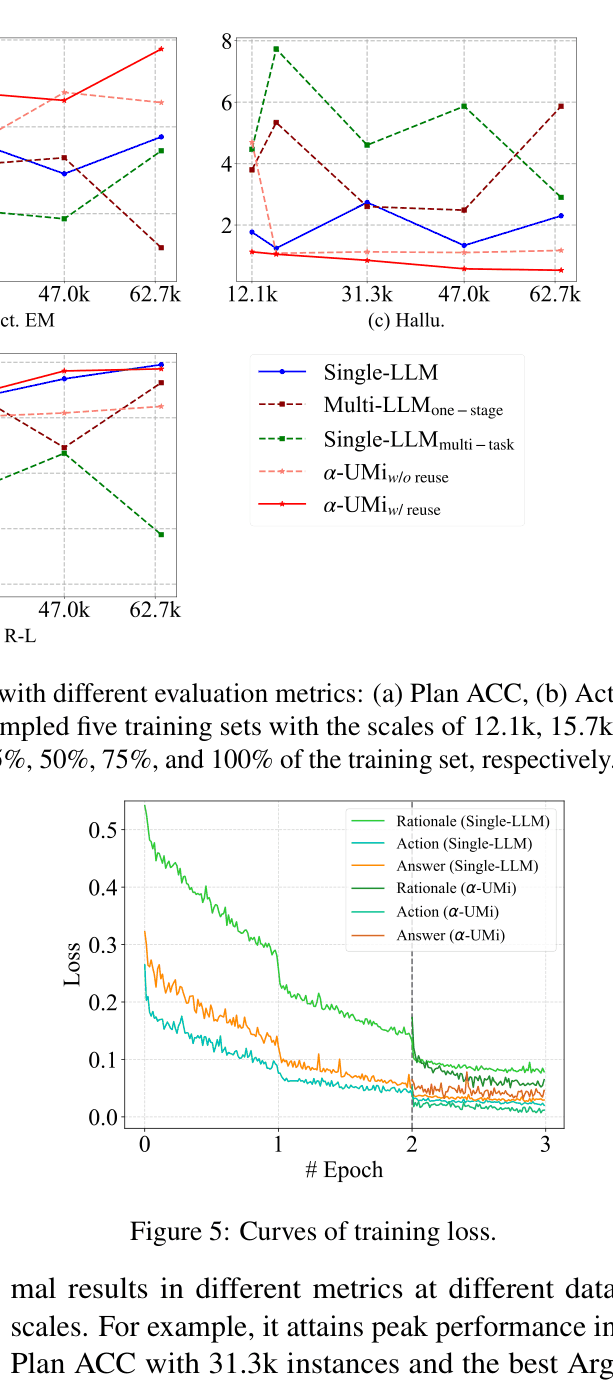
- +5.68 Plan ACC (Planning Accuracy) improvement on ToolBench (In-domain) using LLaMA-2-7B compared to a single-LLM baseline
- +10.2 pass rate improvement over ToolLLaMA on ToolBench real-time evaluation
- Surpasses Single-LLM agents using 13B models while using only 7B models for the multi-agent components, proving small specialized models can beat larger monolithic ones
Breakthrough Assessment
7/10
Strong empirical evidence that decomposing agent functions enables smaller models to compete with larger ones. The Global-to-Local fine-tuning strategy is a practical innovation for maximizing small model capacity.