📝 Paper Summary
Mathematical Reasoning
Tool-augmented LLMs
ToRA trains open-source models to solve complex math problems by interleaving natural language reasoning with program execution, refining performance via imitation learning on corrected tool-use trajectories.
Core Problem
LLMs struggle with complex mathematics requiring precise calculation, while pure program-based methods lack the semantic planning needed for abstract reasoning.
Why it matters:
- Natural language models often make arithmetic errors or hallucinate during complex symbolic manipulation.
- Program-only approaches struggle when problems are not easily formalizable into a single script.
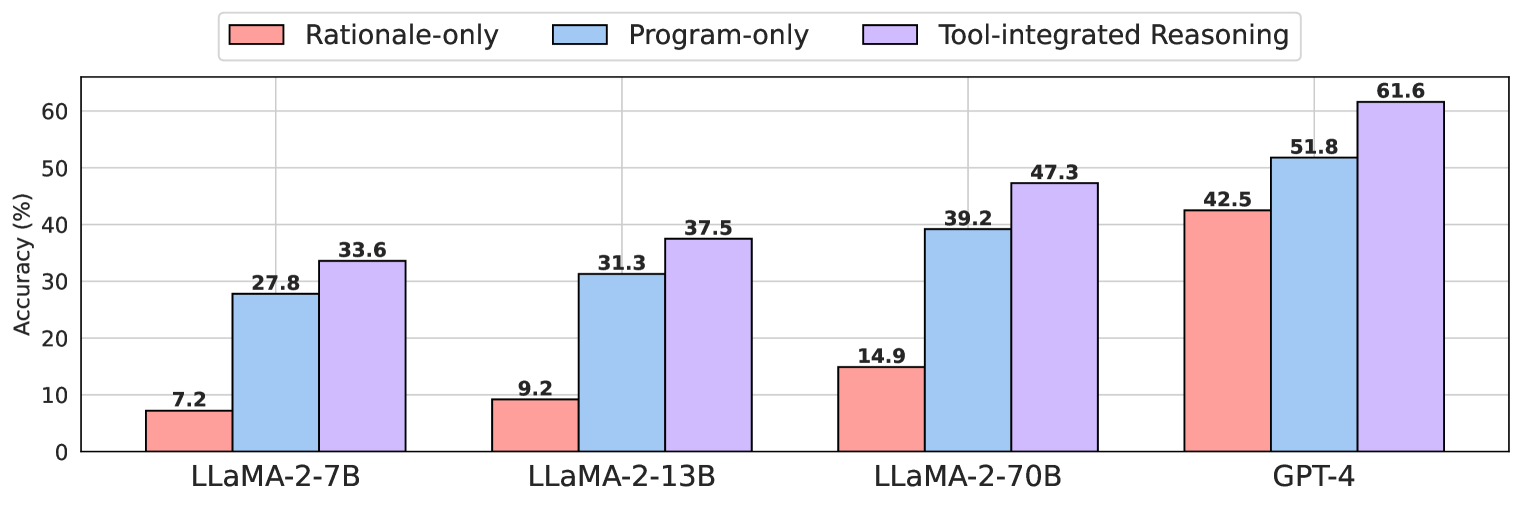
- Existing open-source models lag significantly behind proprietary models (like GPT-4) in mathematical reasoning tasks.
Concrete Example:
In geometry or algebra, a standard CoT (Chain-of-Thought) model might correctly derive a formula but fail the final arithmetic, whereas a program-only model might fail to interpret the diagram description before calculating.
Key Novelty
Output Space Shaping with Interleaved Reasoning
- Interleaves natural language rationale with Python code generation, allowing the model to plan in text and offload computation to tools.
- Improves training data density by not just filtering valid samples, but actively correcting invalid trajectories using a 'teacher' model to create new valid training examples.
Architecture
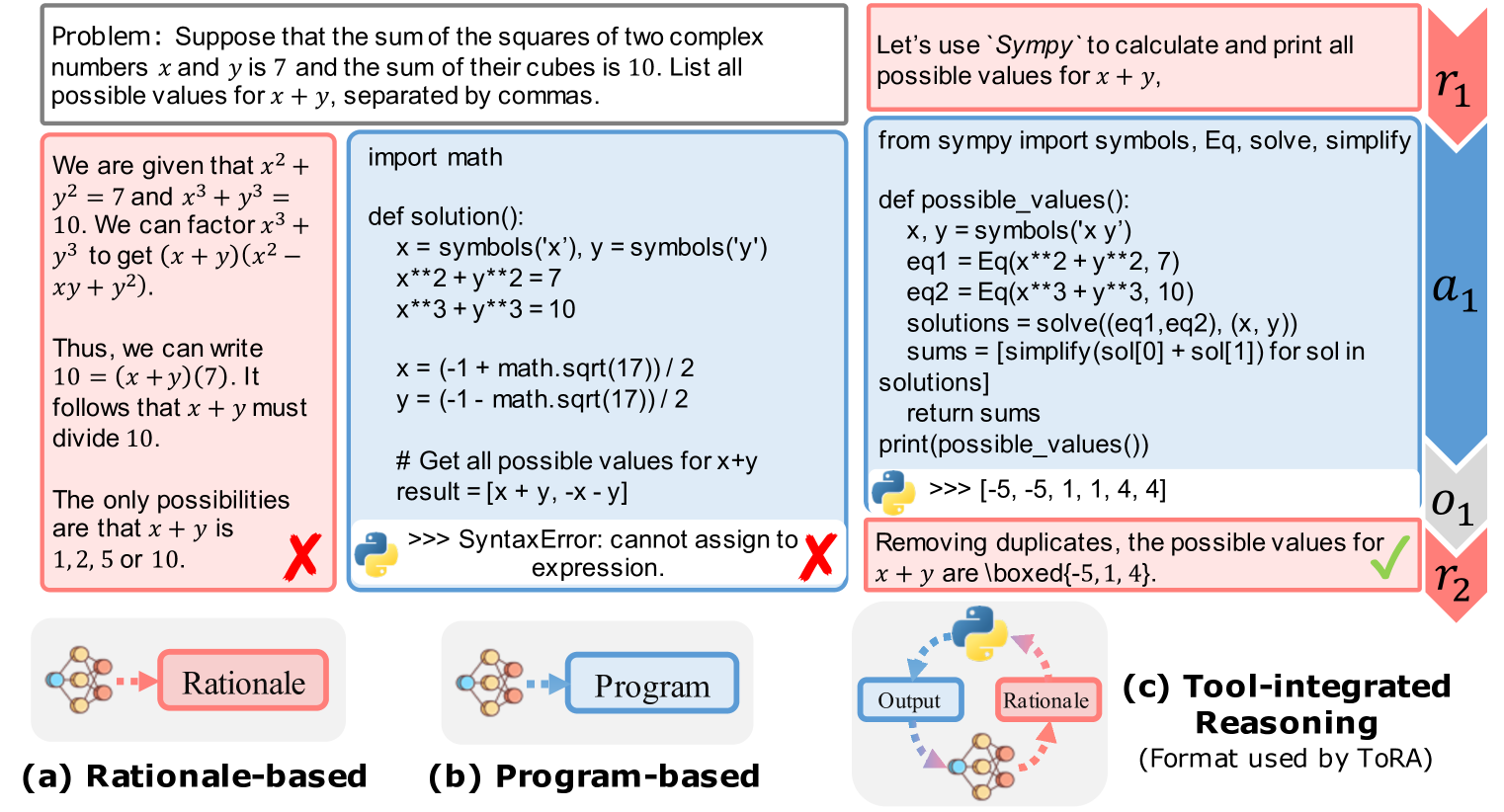
The ToRA inference and training pipeline compared to CoT and PAL.
Evaluation Highlights
- ToRA-Code-34B achieves 50.8% accuracy on the MATH dataset, outperforming GPT-4 Chain-of-Thought (42.5%) by 8.3 percentage points.
- ToRA-Code-7B reaches 44.6% on MATH, surpassing the previous state-of-the-art open-source model WizardMath-70B (22.7%) by nearly 22 percentage points.
- Across 10 diverse math datasets, ToRA models achieve 13%-19% absolute improvement on average compared to state-of-the-art open-source baselines.
Breakthrough Assessment
8/10
Significant breakthrough for open-source models, enabling a 34B model to beat GPT-4 CoT on the hardest math benchmark. The output space shaping (correction) technique is a valuable contribution to data-centric AI.