📝 Paper Summary
Tool-use post-training
Synthetic data generation
Toucan synthesizes a massive dataset of 1.5 million agent trajectories by interacting with nearly 500 real-world Model Context Protocol servers to train LLMs in complex, multi-turn tool use.
Core Problem
Open-source tool-agent development is hindered by a lack of high-quality, permissively licensed training data that captures the complexity of real-world tool interactions.
Why it matters:
- Existing datasets lack tool diversity, authentic tool responses, or multi-turn complexity, limiting agent capability in production environments
- Current approaches often rely on simulated toolsets or simple single-turn interactions, failing to prepare agents for edge cases and failures
Concrete Example:
Previous datasets might simulate a weather API call with a hallucinated JSON response. Toucan connects to a real Weather MCP server, executes the actual tool, captures the real API output (including errors), and generates a trajectory based on that ground truth.
Key Novelty
Toucan Dataset & Pipeline
- Leverages the Model Context Protocol (MCP) to standardize connections to diverse real-world tools (filesystems, databases, APIs) rather than custom implementations
- Uses a 'self-simulation' pipeline where teacher models generate tasks based on real MCP specs, execute them against live servers, and filter results based on execution success
- Introduces extension mechanisms for 'irrelevance' (rejecting unsolvable queries) and multi-turn dialogue to simulate realistic user-agent interactions
Architecture
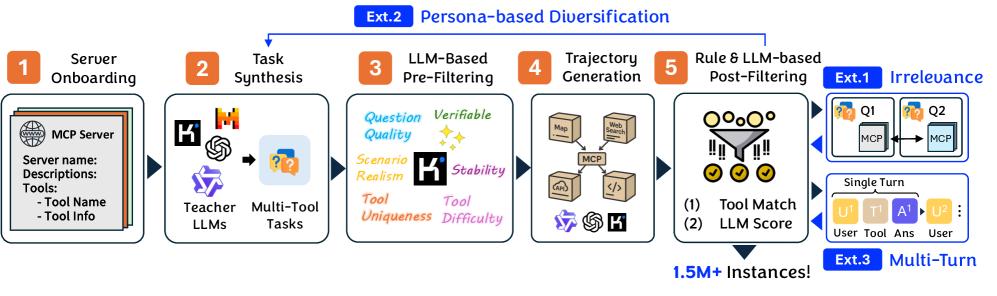
The complete Toucan data construction pipeline from MCP server onboarding to final trajectory filtering and extensions.
Evaluation Highlights
- Toucan-tuned models achieve state-of-the-art performance on the MCP-Universe benchmark, consistently outperforming leading models of comparable size
- Outperforms larger closed-source models on BFCL V3 benchmark in function calling accuracy across single and multi-turn scenarios
- Demonstrates substantial improvements on τ-Bench and τ²-Bench in tool selection, execution fidelity, and multi-turn reasoning
Breakthrough Assessment
8/10
Significantly scales up open-source agent training data using real-world protocols (MCP) rather than simulations. The reliance on live execution for ground truth is a strong differentiator.