📝 Paper Summary
Multi-call tool use with flexible plan
RL-based tool use
Tool-Star empowers LLMs to collaboratively use multiple tools (search, browser, code interpreter) via a self-critic reinforcement learning framework that incentivizes tool interaction through hierarchical rewards.
Core Problem
Current RL-based reasoning methods primarily focus on single-tool interactions or internal thought processes (Chain-of-Thought), failing to effectively integrate multiple heterogeneous tools (e.g., search + code) for complex problem-solving.
Why it matters:
- Real-world tasks require diverse capabilities—combining dynamic information seeking (search) with precise calculation (code)—which single-tool models struggle to coordinate.
- Existing SFT-based tool approaches rely on limited human demonstrations, while prior RL approaches often fail to incentivize the collaborative usage of multiple tools.
- Without proper incentives, models may either overuse tools (inefficiently) or revert to hallucinating answers instead of verifying them externally.
Concrete Example:
When solving a math problem that requires current exchange rates, a standard CoT model might hallucinate the rate. A single-tool model might search for the rate but fail to calculate the conversion accurately. Tool-Star searches for the rate, then invokes a code interpreter to perform the precise calculation.
Key Novelty
Multi-Tool Self-Critic RL with Hierarchical Rewards
- Synthesizes a curriculum of tool-use data by injecting 'hint' tokens (e.g., 'Logical Verification', 'Answer Reflection') into standard reasoning traces to force tool invocation.
- Uses a hierarchical reward function during RL that explicitly rewards valid multi-tool collaboration (using both search and code in one trace) alongside correctness and format adherence.
- Interleaves a self-critic phase where the model learns to predict its own rewards, helping it internalize the complex requirements of multi-tool coordination.
Architecture
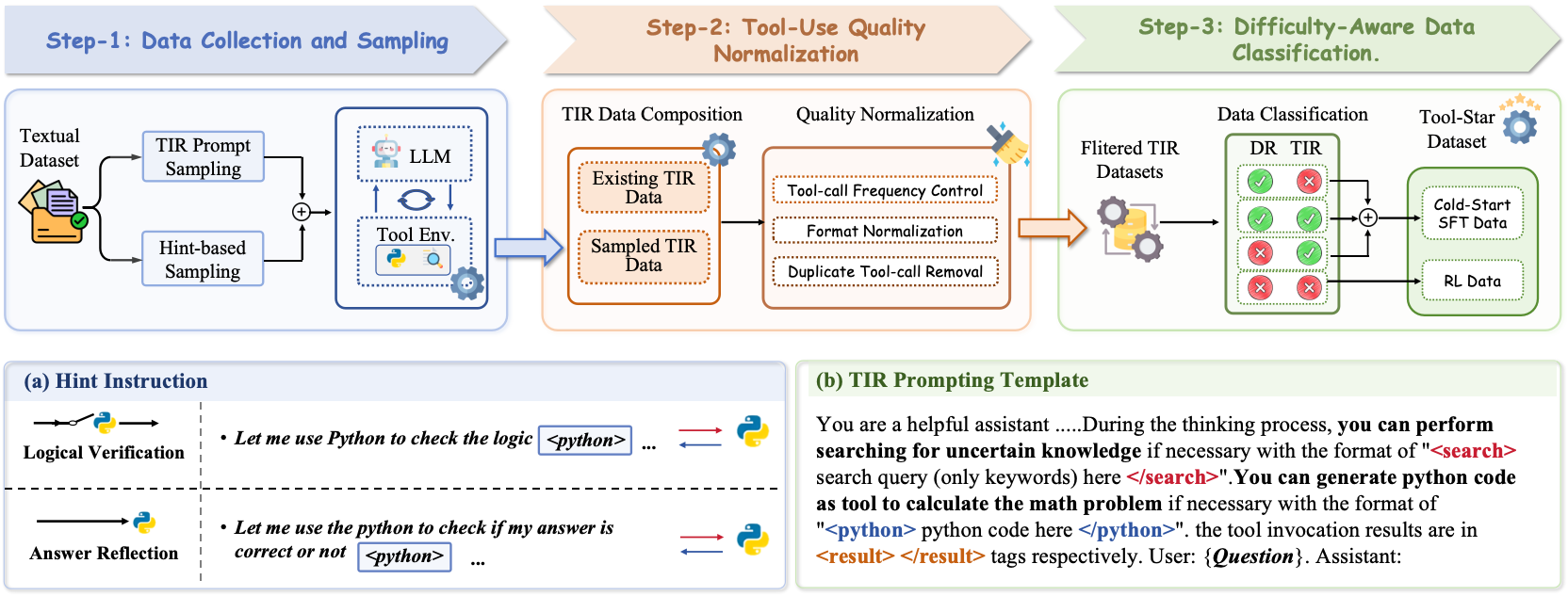
The Data Synthesis Pipeline and Training Framework. It visualizes how text-only data is converted to tool trajectories via hint injection, followed by the two-stage training (Cold-Start SFT -> Multi-Tool Self-Critic RL).
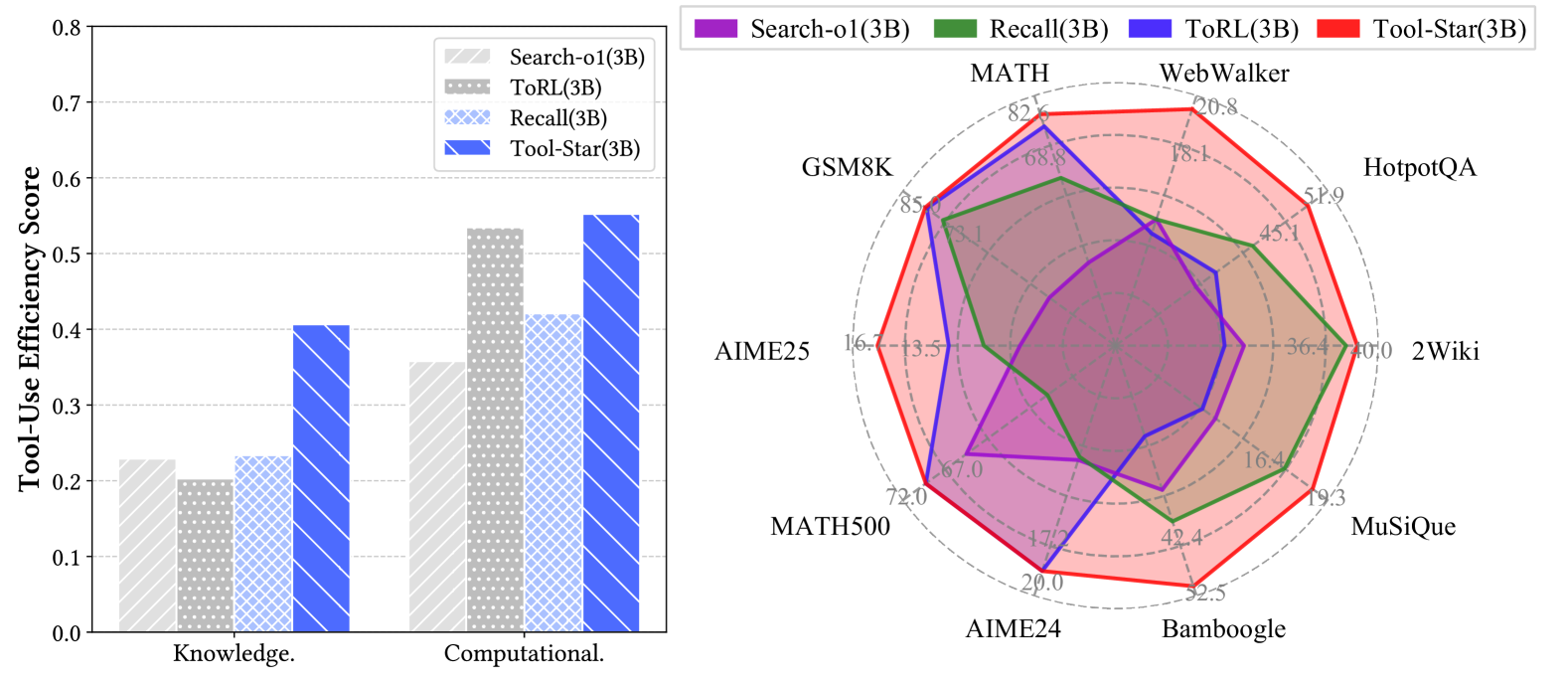
Evaluation Highlights
- Achieves 65.4% on MATH500, outperforming GPT-4o-mini (60.6%) and the base Llama-3.1-8B-Instruct (52.2%).
- Outperforms open-source tool-use baselines like Qwen-Agent and ToolACE on challenging benchmarks like AIME24 (15.5%) and HotpotQA (56.4%).
- Demonstrates high tool-use efficiency, solving tasks with fewer steps than baseline agents while maintaining higher accuracy.
Breakthrough Assessment
8/10
Strong methodological contribution in scaling tool-use data synthesis and designing a reward structure that successfully forces multi-tool collaboration, backed by comprehensive gains across diverse benchmarks.