📝 Paper Summary
Agentic AI
Reinforcement Learning (RL) for Reasoning
ToRL scales reinforcement learning directly on base models to autonomously discover optimal tool-use strategies, bypassing the limitations of supervised fine-tuning on predetermined trajectories.
Core Problem
Existing Tool-Integrated Reasoning (TIR) methods rely on Supervised Fine-Tuning (SFT) from distilled trajectories, which restricts models to imitating fixed patterns and prevents exploration of optimal strategies.
Why it matters:
- Pure language models struggle with complex calculations and precise equation solving compared to code-augmented models
- Imitation-based SFT limits models to human-designed or distilled tool usage patterns, hindering the emergence of novel or more efficient reasoning paths
- Prior RL approaches typically start from SFT-aligned models, obscuring whether tool capabilities can emerge from scratch through pure reward signals
Concrete Example:
When solving a complex math problem, a standard SFT model might blindly follow a fixed 'reason-then-code' pattern it was trained on. In contrast, a ToRL model might attempt code, fail with a syntax error, self-correct based on the error message, and then switch to analytical reasoning, a behavior learned dynamically through exploration.
Key Novelty
Tool-Integrated Reinforcement Learning (ToRL) from Base Models
- Applies reinforcement learning directly to base models (without prior instruction tuning) with a code interpreter integrated into the interaction loop
- Allows the model to learn tool invocation, code generation, and self-correction solely through outcome-based rewards (correct/incorrect answer) rather than imitating demonstrations
Architecture
Conceptual flow of the Tool-Integrated Reasoning (TIR) rollout process.
Evaluation Highlights
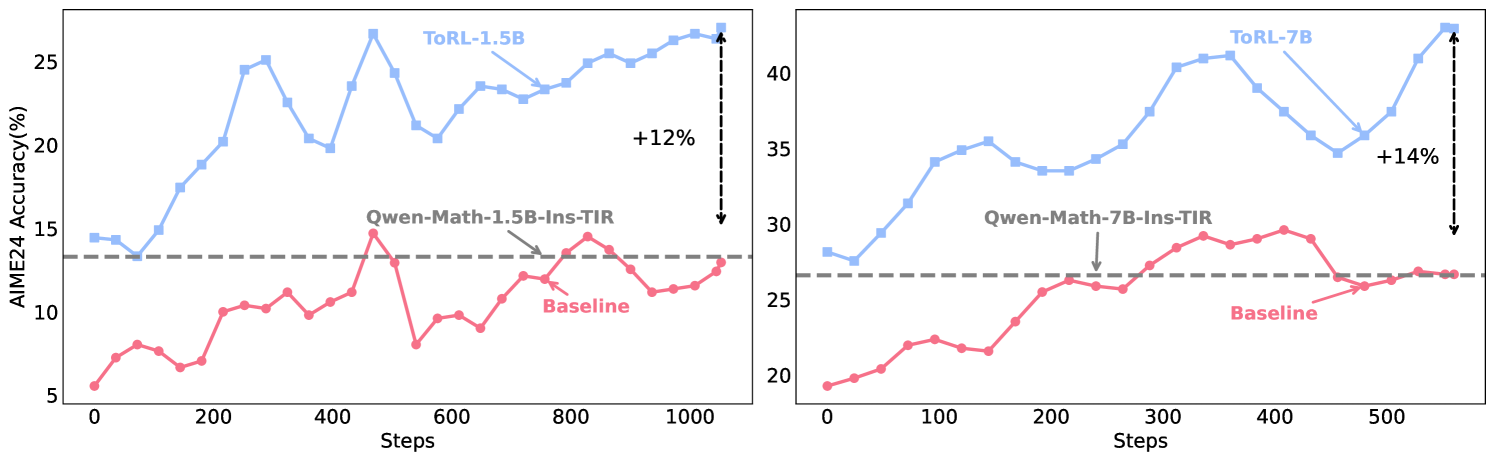
- ToRL-7B achieves 43.3% accuracy on AIME24, surpassing the best existing Tool-Integrated Reasoning (TIR) model by ~17% (absolute)
- Outperforms standard RL training without tool integration by ~14% (absolute) on AIME24
- ToRL-1.5B achieves 48.5% average accuracy across benchmarks, beating Qwen2.5-Math-1.5B-Instruct-TIR (41.3%)
Breakthrough Assessment
8/10
Strong empirical evidence that RL can induce complex tool-use behaviors from scratch in base models, significantly outperforming SFT-based baselines. The emergence of self-correction without explicit instruction is a key finding.