📝 Paper Summary
Tool-use post-training
RL-based tool use
TL-Training improves LLM tool use by filtering error-prone training data, applying adaptive weights to key tool-name tokens, and using PPO with rewards tailored to specific tool-invocation error types.
Core Problem
Standard supervised fine-tuning for tool use suffers from noisy training data (where models mimic errors), ignores that certain tokens are more critical than others, and lacks mechanisms to correct specific error categories.
Why it matters:
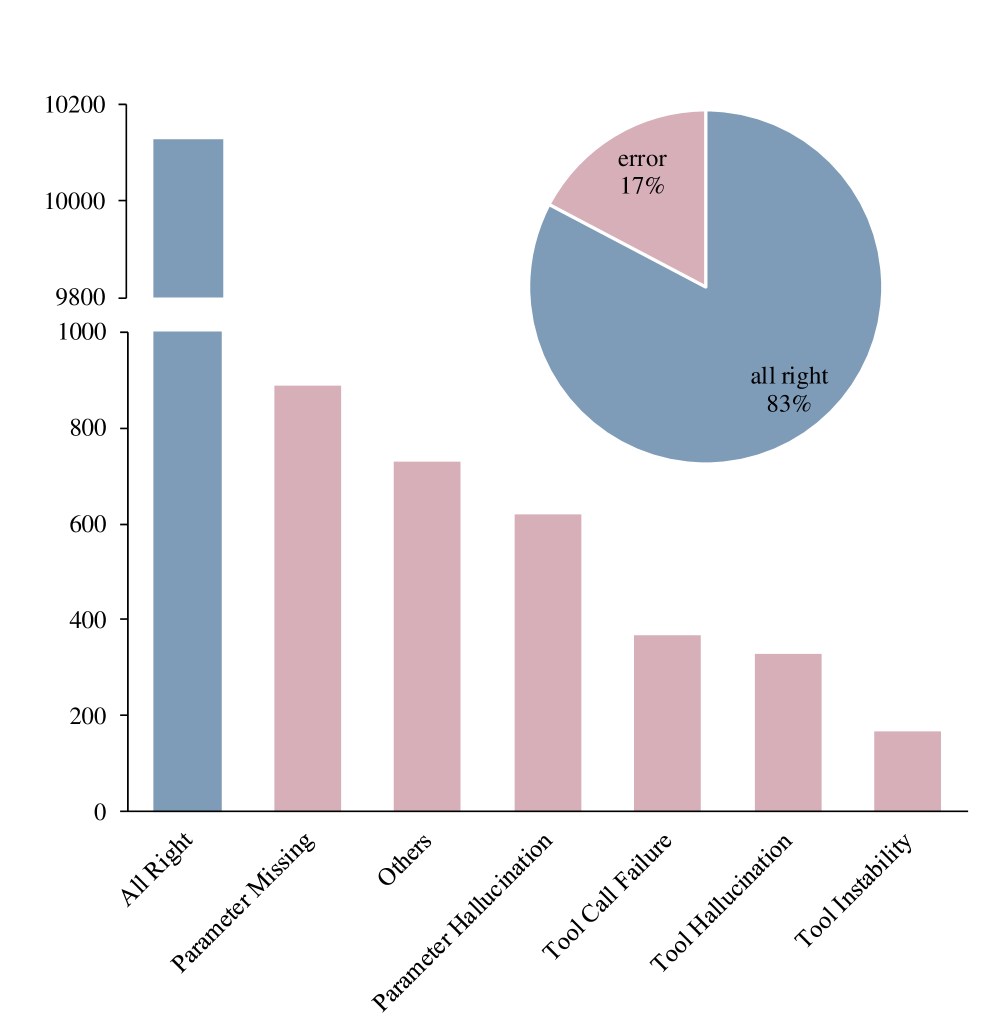
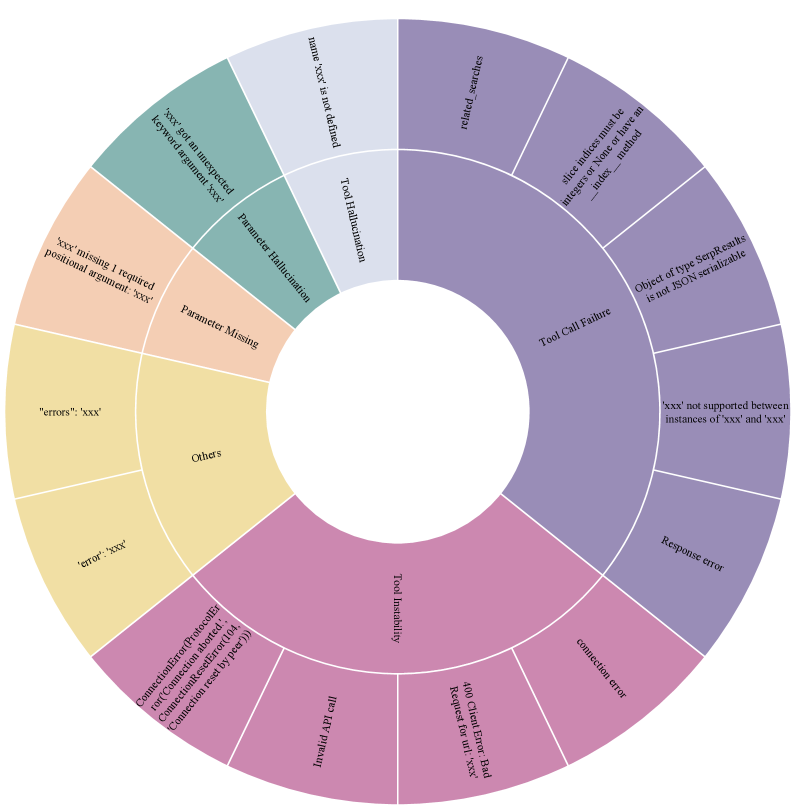
- 17% of high-quality training data (e.g., RoTLLaMA) contains tool-calling errors, causing models to learn incorrect behaviors
- Existing SFT treats all tokens equally, even though correcting just the first token of a tool name often fixes the entire prediction
- Current models like ToolLLaMA-2-7B-v2 achieve only ~80% of GPT-4's performance, indicating significant bottlenecks in standard training paradigms
Concrete Example:
In a trajectory where a model should call 'calculate_loan', the training data might contain a path where the model hallucinates 'get_loan_info'. Standard SFT forces the model to learn this hallucination. TL-Training identifies this error via feedback analysis and masks the loss so the model doesn't learn from the mistake.
Key Novelty
TL-Training (Task-Feature-Based Framework)
- Mitigates Adverse Effects (MAE): Automatically detects erroneous tool calls in training data by analyzing feedback and masks their loss to prevent back-propagation
- Prioritizing Key Tokens (PKT): Adaptively increases loss weights for the first token of a tool name and tokens sharing prefixes with other tools, forcing the model to focus on critical decision points
- Error-Specific Reward Mechanism: Defines distinct penalties for tool hallucinations, parameter errors, and missing arguments, optimizing the model via PPO (Proximal Policy Optimization)
Architecture
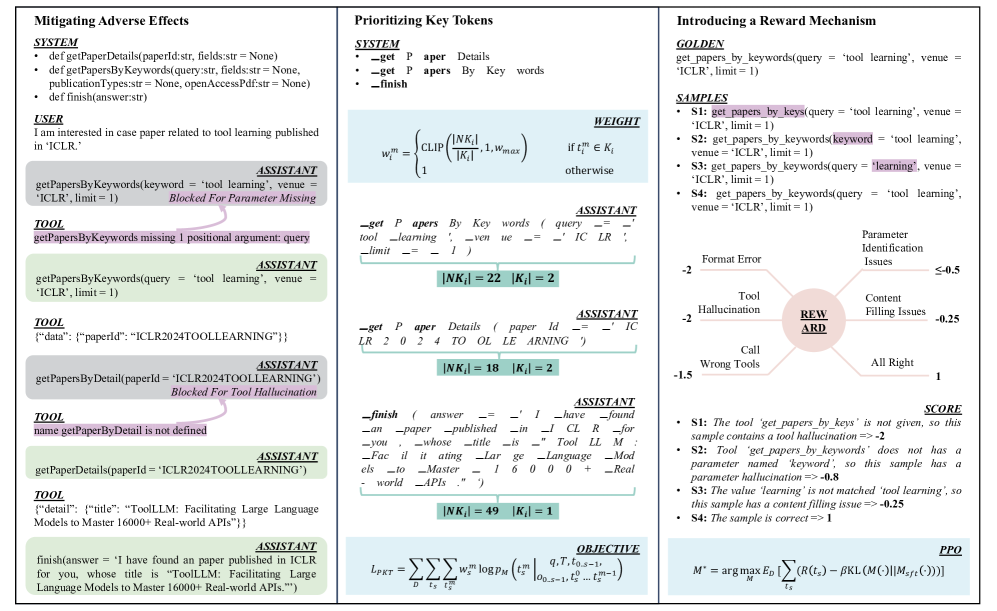
The TL-Training framework pipeline, illustrating the three main components: Adverse Effects Mitigation (MAE), Key Tokens Prioritization (PKT), and the Reward Mechanism for RL.
Evaluation Highlights
- +15.78% performance improvement on ToolAlpaca (single-turn) compared to GPT-4-turbo using TL-CodeLLaMA-2
- Achieves 5.64% total error rate on multi-turn benchmarks, second only to GPT-4o (4.76%) and outperforming Qwen-2-Instruct (7.49%)
- Matches or exceeds closed-source performance using only 1,217 training samples, significantly less than typical large-scale datasets
Breakthrough Assessment
7/10
Strong empirical results with very little data (1.2k samples). The idea of masking erroneous SFT trajectories and weighting key tokens is intuitive and effective, though the architectural novelty is moderate.