📝 Paper Summary
Multi-call tool use with flexible plan
Multi-turn w. user interactions
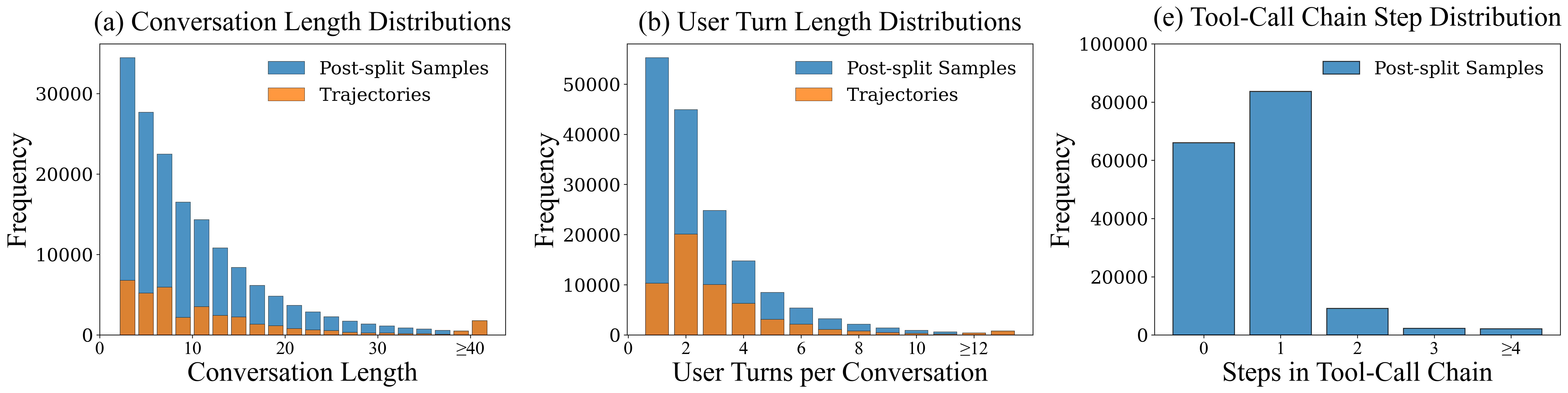
Benchmark datasets
ToolMind is a large-scale tool-use dataset created via multi-agent simulation and a novel function graph that improves LLM performance on complex, multi-turn benchmarks by enforcing rigorous turn-level reasoning quality.
Core Problem
Existing tool-use datasets suffer from limited scale, lack of explicit reasoning traces, insufficient multi-turn dynamics (like clarification questions), and rely on coarse trajectory-level validation that misses intermediate errors.
Why it matters:
- Real-world user requests are often under-specified, requiring agents to proactively ask for clarification rather than hallucinating parameters
- Turn-level errors in training data (even in successful trajectories) propagate during training, degrading the model's ability to reason correctly step-by-step
- Current open-source datasets lack the diversity and dynamic user-assistant interactions needed to train robust generalist agents
Concrete Example:
A user might ask 'What's the weather in Beijing?' without specifying a time. A standard dataset might force an immediate API call with a hallucinated date. ToolMind captures the dynamic where the agent asks 'For which date?' and the user clarifies, preserving the reasoning chain.
Key Novelty
Graph-Guided Multi-Agent Simulation with Fine-Grained Filtering
- Constructs a 'Function Graph' where edges represent semantic compatibility between one tool's output and another's input, enabling the sampling of complex, realistic function chains via random walks
- Simulates interactions using three distinct agents (User, Assistant, Tool) to generate dynamic multi-turn conversations, including clarification requests and tool execution feedback
- Applies a two-stage filtering process that validates not just the final outcome (trajectory-level) but also scrubs individual erroneous steps (turn-level) to ensure high-quality reasoning traces
Architecture
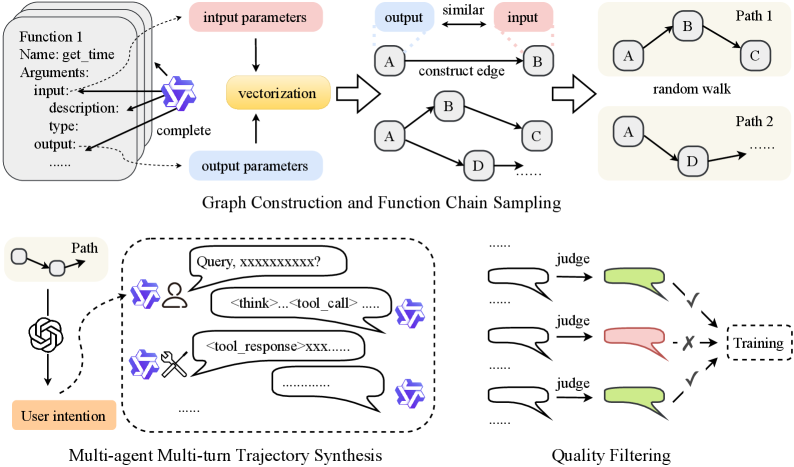
The Data Synthesis Pipeline: From function graph construction to multi-agent simulation and two-stage filtering.
Evaluation Highlights
- +13.6% improvement on Tau-bench (Retail) for Qwen3-14B after fine-tuning on ToolMind compared to base model
- Surpasses GPT-4o on BFCL-v4 (Multi-Turn) accuracy with Qwen3-14B (79.24% vs 72.82%)
- +5.4% improvement on Tau-2-bench (Retail) for Qwen3-8B after fine-tuning compared to base model
Breakthrough Assessment
8/10
Significant because it addresses the data bottleneck for complex tool use. The method of using a function graph for chain sampling and rigorous turn-level filtering yields SOTA results on difficult benchmarks like Tau-bench.