📝 Paper Summary
Multi-turn w. user interactions
Tool-use post-training
AskToAct improves tool-using agents by automatically generating clarification data from tool parameters and training models to self-correct errors during clarification dialogues.
Core Problem
Real-world user queries for tools are often ambiguous or incomplete, but current LLMs struggle to clarify intent effectively and lack mechanisms to recover from errors during multi-turn interactions.
Why it matters:
- Current approaches rely on small, manually annotated datasets that fail to capture the diversity of real-world ambiguity.
- Without error recovery, models accumulate mistakes (e.g., asking redundant questions) in multi-turn dialogues, degrading user experience and tool invocation accuracy.
- Unspecified queries pose safety risks if models hallucinate parameters instead of asking for clarification.
Concrete Example:
A user asks 'Book a hotel.' A standard model might hallucinate a location or date. A clarification model might ask 'Where?', but if it then forgets the answer and asks 'Where?' again (redundant clarification), the interaction fails. AskToAct detects this redundancy and corrects it.
Key Novelty
Self-Correcting Clarification via Reverse-Engineering Tool Parameters
- Reverse-engineers ambiguous queries by removing parameters from valid tool calls, using the removed parameters as ground truth for what needs clarification.
- Injects synthetic errors (e.g., redundant questions) into training dialogues and trains the model to detect and correct them, enabling robustness.
- Uses selective masking during training to learn from error-correction pairs without reinforcing the erroneous behavior itself.
Architecture
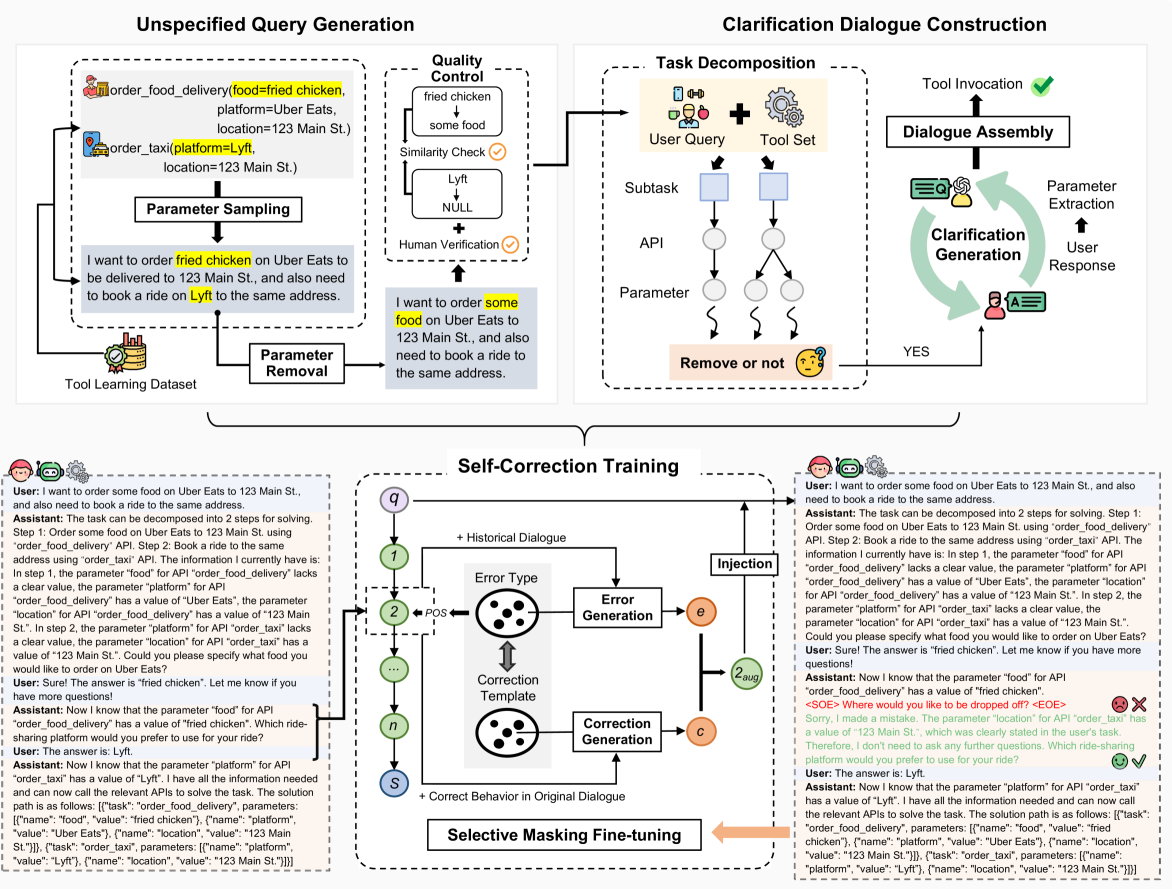
The overall AskToAct framework, illustrating the data construction pipeline (left) and the self-correction training paradigm (right).
Evaluation Highlights
- Recovers 57.08% of unspecified intents (Intent Recovery Rate), significantly outperforming baselines like GPT-4 (54.79%) and ToolLLaMA (35.84%).
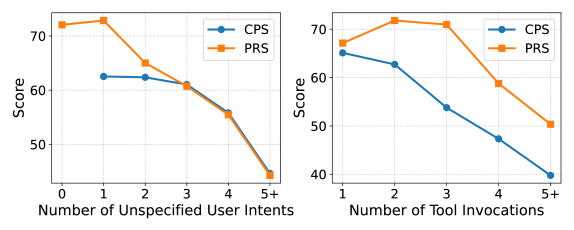
- Improves clarification efficiency by reducing the average number of turns by 10.46% compared to the base model while maintaining high accuracy.
- Achieves 81.65% tool selection accuracy and 68.31% parameter resolution accuracy, surpassing previous clarification-focused methods.
Breakthrough Assessment
8/10
Offers a scalable, automated solution to the data scarcity problem in clarification research and introduces a novel self-correction mechanism that directly addresses error accumulation.