📝 Paper Summary
Interactive tool-use agents
Reinforcement Learning for Agents
Multimodal Agents (Speech-Text)
The paper introduces a reinforcement learning framework that combines mixed-task math training to sustain exploration with an LLM judge providing turn-level rewards to improve credit assignment in long-horizon interactive tool use.
Core Problem
Standard reinforcement learning fails in complex, multi-turn tool-use scenarios because trajectory-level rewards are too sparse for credit assignment, and agents tend to become overconfident and stop exploring.
Why it matters:
- Real-world agent interactions (like booking tickets) involve long, multi-turn conversations where a single mistake can ruin the outcome, making credit assignment difficult
- As RL training progresses, models often shorten their reasoning chains and stop self-correcting (overconfidence), leading to avoidable errors in complex tasks
- Current approaches relying on static trajectories cannot handle the dynamic variability of real-time user interactions, especially in multimodal (voice) contexts
Concrete Example:
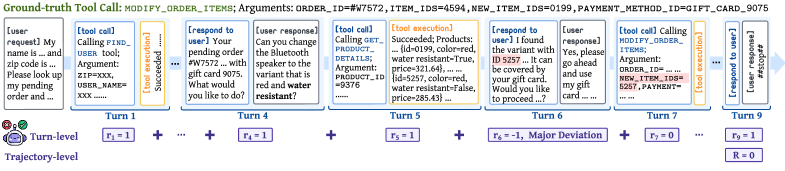
In a retail exchange task, an overconfident agent might cancel an order immediately without confirming with the user. A standard RL agent might eventually get a zero reward at the end of the conversation, but it won't know specifically that the *lack of confirmation* at turn 3 was the cause, unlike the proposed method which penalizes that specific turn.
Key Novelty
Turn-level Adjudicated Reinforcement Learning (TARL)
- Uses an LLM-based judge to evaluate every single turn of the conversation, providing immediate granular rewards (-1, 0, 1) rather than waiting for the final outcome
- Incorporates mixed-task training with medium-difficulty math problems to force the model to maintain long Chain-of-Thought (CoT) reasoning capabilities, preventing the 'collapse' of exploration where agents become lazy and short-sighted
Architecture
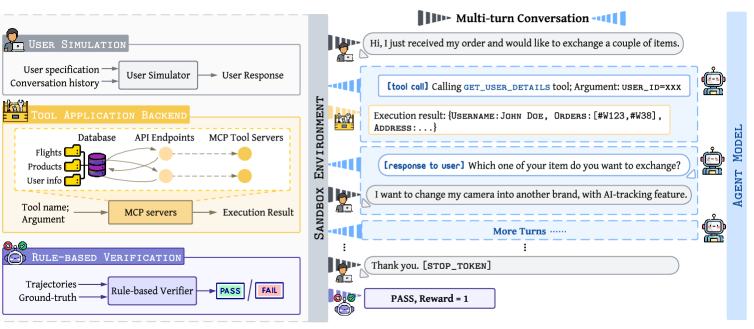
The Sandbox Environment and TARL training loop
Evaluation Highlights
- +6% improvement in pass rate on text-based tasks compared to strong RL baselines (PPO/GRPO without turn-level rewards)
- +9% improvement in single-sample (pass^1) performance for GRPO over the Qwen3-8B base model on Retail domain tasks
- +20% improvement in pass rate for the multimodal agent on speech-based user simulation compared to the base multimodal LLM
Breakthrough Assessment
7/10
Solid methodological improvement for agentic RL by addressing the specific problems of sparse rewards and exploration collapse. The extension to multimodal (speech) agents demonstrates practical utility.