📝 Paper Summary
RL-based Tool Use
Tool-use post-training
ResT stabilizes reinforcement learning for tool-use agents by reshaping policy gradients based on token entropy, prioritizing structured tokens (names, parameters) early and reasoning tokens later via a curriculum.
Core Problem
Training tool-use agents with standard RL is inefficient because sparse outcome rewards cause high gradient variance, and rule-based rewards often neglect reasoning tokens.
Why it matters:
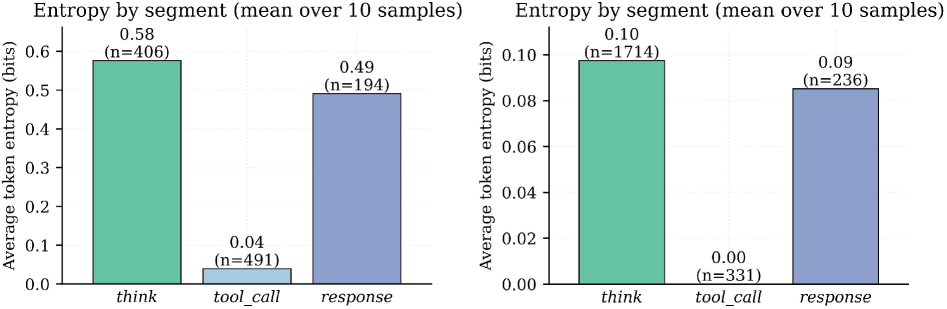
- Current RL methods for tool use suffer from high variance due to the 'needle-in-a-haystack' nature of critical tokens (tool names/args) amidst general text
- Uniformly treating all tokens dilutes reward signals, making credit assignment difficult for multi-turn tasks where reasoning is crucial but sparse
- Existing systems are sample-inefficient and computationally expensive due to multi-turn rollouts
Concrete Example:
In a tool-call task, a model might generate a long reasoning chain but fail slightly on a parameter name. Standard outcome rewards give a zero score, providing no signal on which part failed. ResT identifies low-entropy tokens (the parameter name) as critical and weights their gradient updates higher to fix the specific error.
Key Novelty
Entropy-Aware Token-Level Policy Gradient Reshaping (ResT)
- Theoretically links lower token entropy to reduced policy-gradient variance, identifying structured tokens (tool names, parameters) as the most reliable reward carriers
- Reshapes the standard policy gradient by weighting tokens based on their region-level entropy (e.g., higher weights for strict formats, lower for open reasoning)
- Applies a curriculum that dynamically shifts weights: initially prioritizing format/syntax correctness, then gradually upweighting reasoning tokens as training progresses and their entropy stabilizes
Architecture
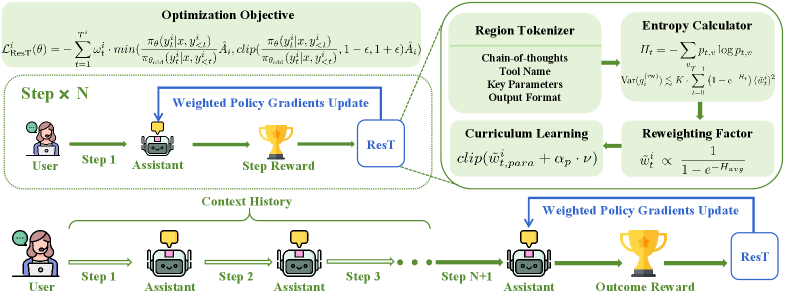
Conceptual overview of ResT. It shows the decomposition of multi-turn tool use into single turns, the entropy-based reshaping of policy gradients, and the curriculum that shifts focus from format to reasoning.
Evaluation Highlights
- Outperforms prior SOTA method (ToolRL/GRPO) by up to 8.76% on the Berkeley Function Calling Leaderboard (BFCL)
- Surpasses GPT-4o by 4.11% on single-turn tool-use tasks and 1.50% on multi-turn base tasks when fine-tuning a 4B parameter model (Qwen3-4B)
- Curriculum-based reshaping improves performance by up to 4.86% compared to static reward weighting strategies
Breakthrough Assessment
8/10
Strong theoretical grounding for token-level weighting in RL, directly addressing the high-variance problem in tool use. Achieving GPT-4o level performance with a 4B model is a significant practical milestone.