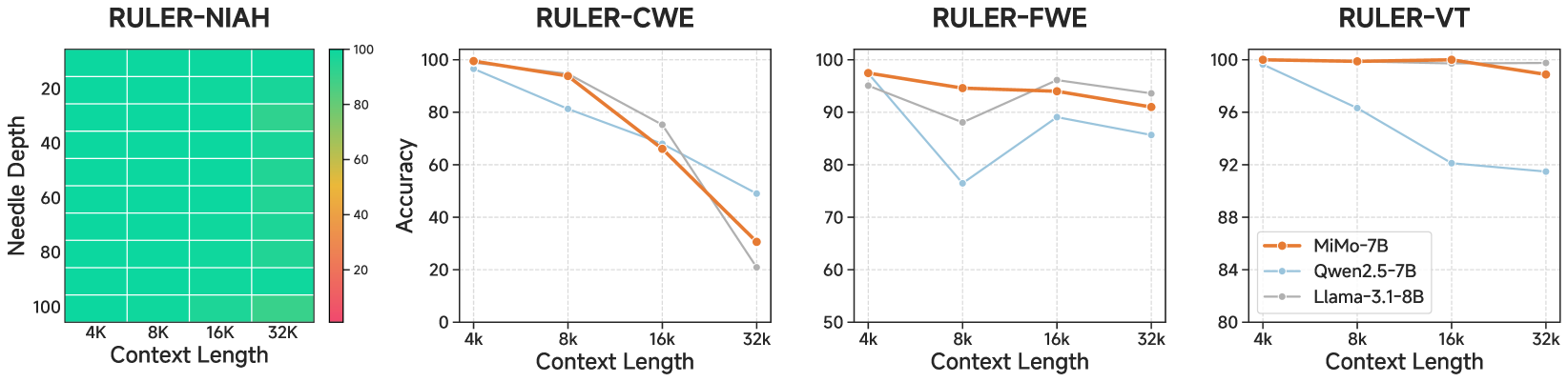
📝 Paper Summary
Reasoning LLMs
Reinforcement Learning for Reasoning
Data Centric AI
MiMo-7B maximizes reasoning potential in a 7B model through a reasoning-dense pre-training data mixture and a reinforcement learning pipeline using verifiable math/code problems with difficulty-weighted rewards.
Core Problem
Most current reasoning models rely on large parameters (e.g., 32B+) to achieve strong performance in math and code, and standard pre-training pipelines often filter out or degrade high-density reasoning content like raw code and LaTeX.
Why it matters:
- Small models (7B) are often considered too weak to simultaneously master math and code reasoning compared to larger counterparts
- Standard heuristic filters in pre-training pipelines inadvertently remove high-value reasoning data (e.g., complex math pages)
- Sparse rewards in RL for reasoning (getting a hard problem right) make it difficult to train robust policies without dense signals
Concrete Example:
Common pre-training extractors often fail to preserve LaTeX equations or code blocks from web pages, turning a rich math tutorial into broken text. MiMo-7B uses a custom HTML extractor to preserve these, ensuring the model sees valid reasoning patterns.
Key Novelty
Full-Stack Reasoning Optimization (Pre-training + Post-training RL)
- Enhances pre-training density by using custom extractors for math/code and a 3-stage data mixture that progressively focuses on STEM content (up to ~70%)
- Incorporates Multi-Token Prediction (MTP) during pre-training to encourage planning and accelerate inference via speculative decoding
- Applies a 'test difficulty driven code reward' in RL, assigning fine-grained scores based on which test cases pass, providing denser signals than simple pass/fail
Architecture
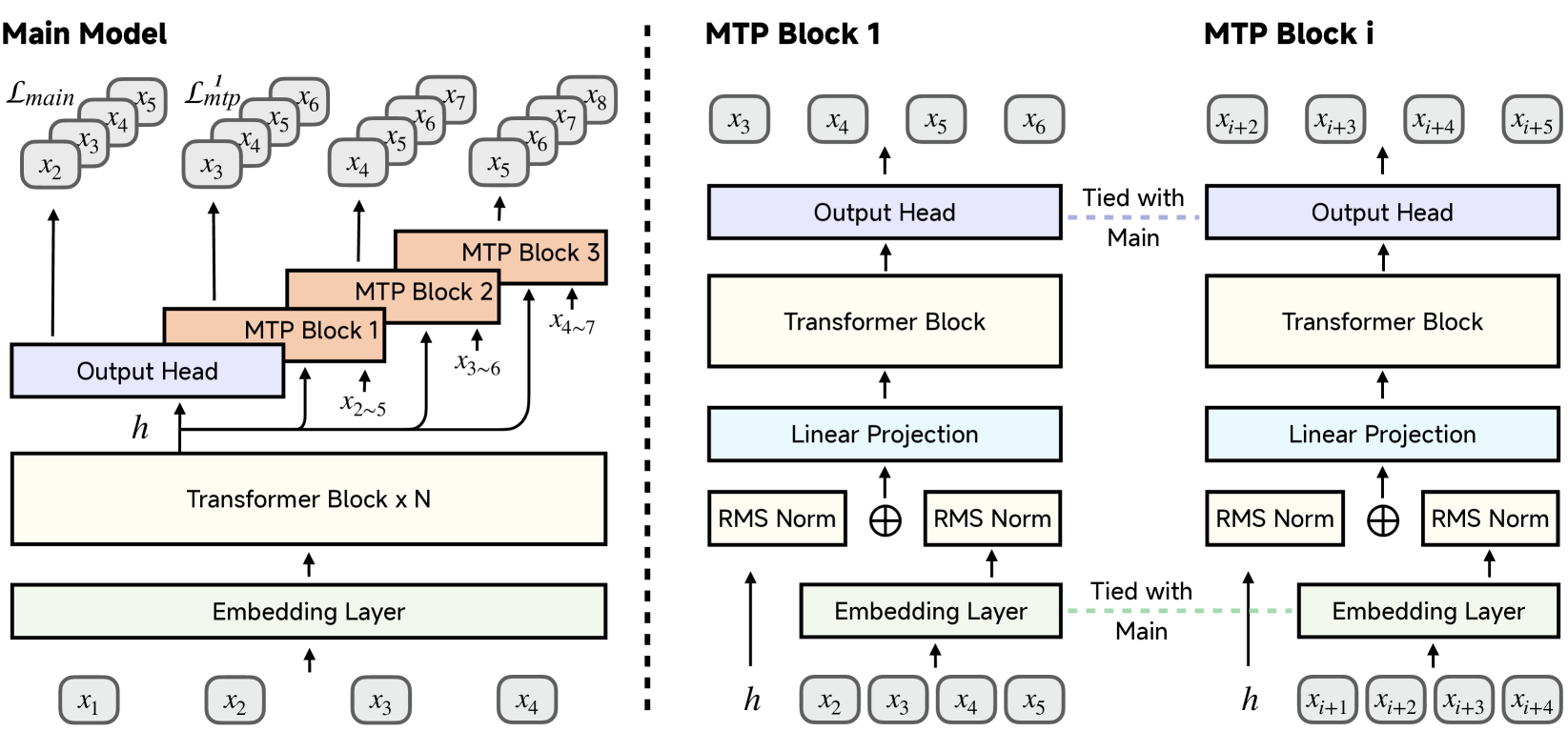
Comparison of MTP (Multi-Token Prediction) setup during pre-training vs. inference.
Evaluation Highlights
- MiMo-7B-RL scores 55.4 on AIME 2025, outperforming OpenAI o1-mini by 4.7 points
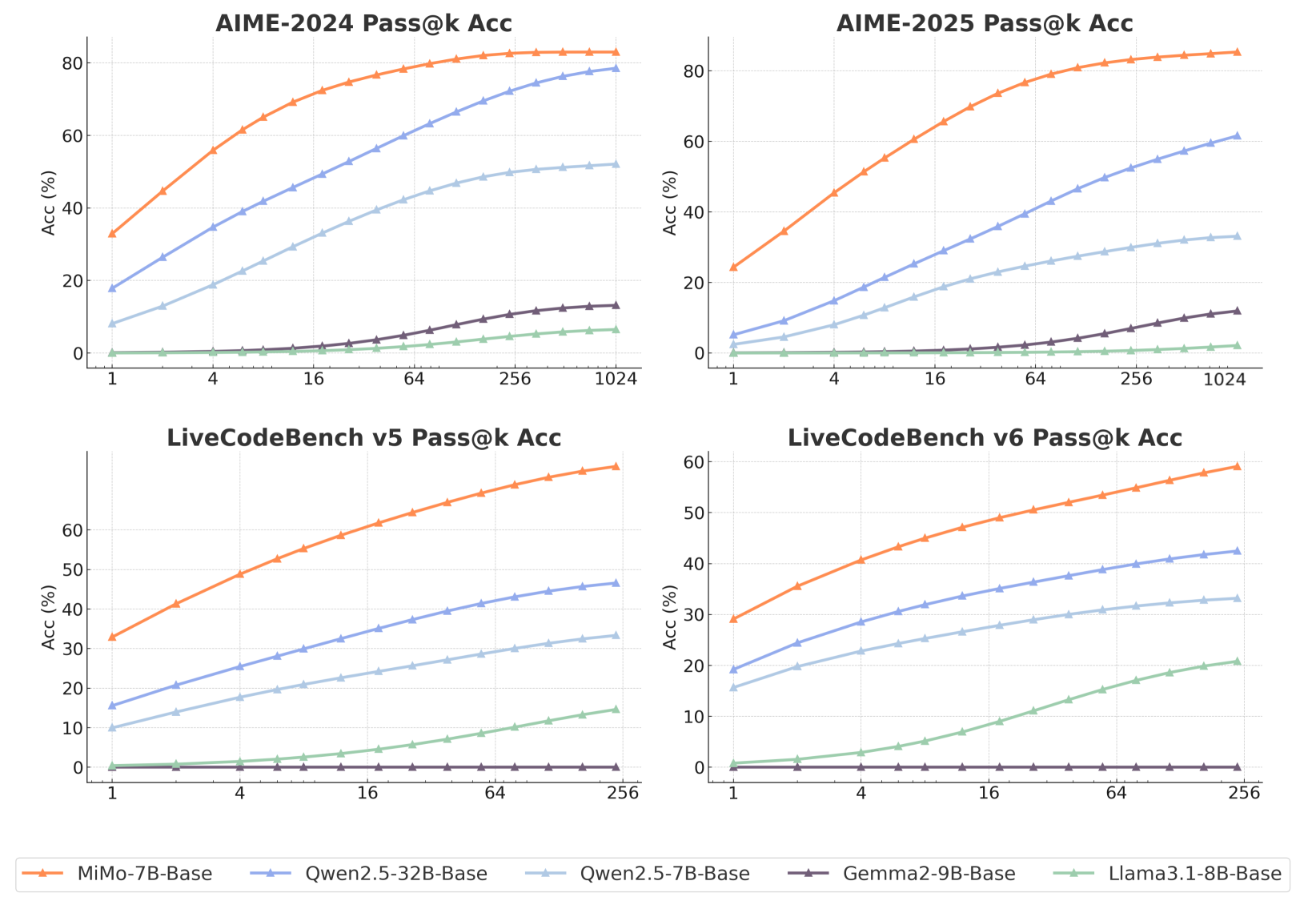
- MiMo-7B-Base scores 32.9 on LiveCodeBench v5 (Pass@1), significantly outperforming Llama-3.1-8B and Qwen-2.5-7B
- RL training on the 7B base model (MiMo-7B-RL-Zero) surpasses the RL performance of a 32B base model on both math and code tasks
Breakthrough Assessment
8/10
Demonstrates that strong reasoning (beating o1-mini) is possible at 7B scale with rigorous data engineering and verifiable RL, challenging the belief that such capabilities require 32B+ parameters.