📝 Paper Summary
Test-time scaling
Tool-augmented reasoning
TUMIX improves reasoning accuracy by running a diverse ensemble of agents—combining text, code, and search capabilities—that iteratively share and refine answers, managed by an adaptive termination policy.
Core Problem
Single-agent LLMs struggle to balance text reasoning, coding, and search within a single context, often underusing tools or failing to identify the best solving strategy for ambiguous questions.
Why it matters:
- Current Code Interpreter implementations often fail to invoke code when needed, relying too heavily on weaker textual reasoning
- Questions rarely provide explicit cues on whether search, code, or pure reasoning is optimal, making single-strategy agents brittle
- Existing test-time scaling methods (like Mixture-of-Agents) focus on scaling LLM count but neglect the diversity of tool-use strategies
Concrete Example:
In complex benchmarks like HLE, a model might attempt to solve a math problem via text and fail due to calculation errors. A standard tool-use agent might stick to one strategy. TUMIX runs both text and code agents in parallel; the text agent's failure is corrected when it sees the code agent's successful execution in the next refinement round.
Key Novelty
Tool-Use Mixture (TUMIX) with Heterogeneous Agents
- Runs 15+ diverse agents in parallel (some pure text, some using Python, some using Google Search/LLM-search) rather than cloning a single 'best' agent
- Implements a 'message passing' refinement where agents update their answers based on the history of *all* other agents' outputs
- Uses an LLM-based judge to dynamically stop refinement when confidence is high, saving compute compared to fixed-round methods
Architecture
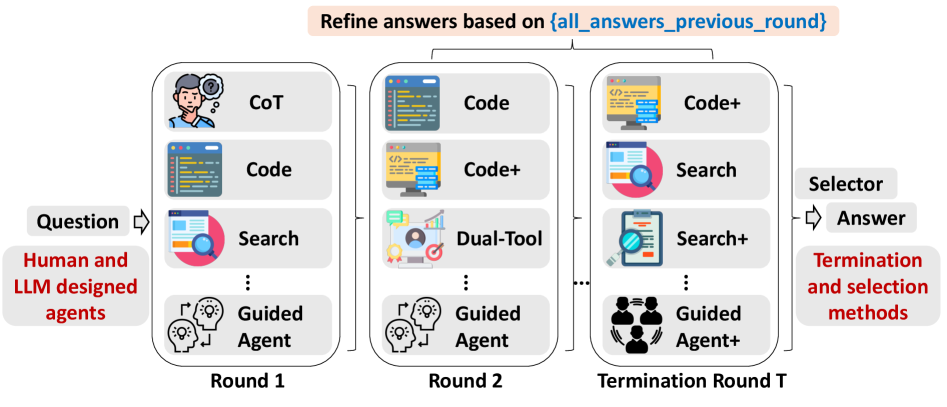
The TUMIX framework showing parallel agents, iterative refinement loops, and aggregation.
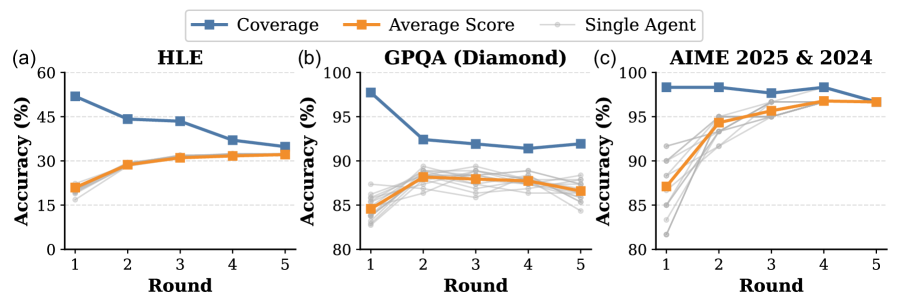
Evaluation Highlights
- +3.55% average accuracy improvement over best-performing test-time scaling baselines (Self-MoA, SciMaster) on Gemini-2.5 models
- Reduces inference costs to ~49% of fixed-round baselines while maintaining accuracy via adaptive early termination
- Raises Gemini-2.5-Pro accuracy on Humanity's Last Exam (HLE) from 21.6% to 34.1% via scaling
Breakthrough Assessment
8/10
Strong empirical results on very hard benchmarks (HLE, GPQA Diamond). Effectively combines tool use with the 'Mixture of Agents' scaling philosophy, addressing the tool-selection bottleneck by simply running all strategies and aggregating.