📝 Paper Summary
Non-autoregressive generation
Sequence modeling
Diffusion models for text
Insertion Language Models (ILMs) generate sequences by inserting tokens at arbitrary positions using a denoising objective that predicts missing tokens and their locations simultaneously, enabling flexible, out-of-order generation without fixed-length constraints.
Core Problem
Autoregressive models (ARMs) struggle with planning and constraints due to rigid left-to-right generation, while Masked Diffusion Models (MDMs) suffer from incoherence due to simultaneous unmasking and cannot handle arbitrary-length infilling because mask counts are fixed.
Why it matters:
- Rigid left-to-right generation fails on tasks requiring lookahead or complex constraint satisfaction (e.g., Zebra puzzles)
- MDMs' reliance on a fixed number of mask tokens makes them unsuitable for tasks where the length of the missing text is unknown (e.g., 'The conference,
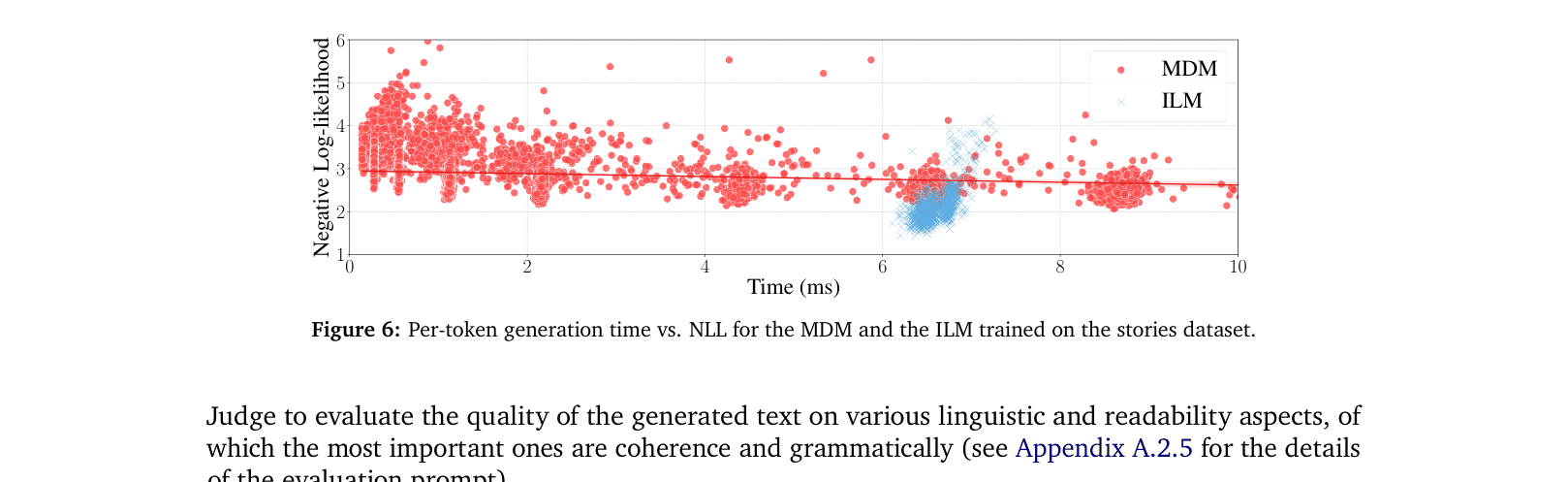
was postponed' vs 'The conference, originally planned for March, was postponed') - Simultaneous unmasking in MDMs breaks token dependencies, producing incoherent outputs like 'The chef added sugar to the dessert to make it healthier'
Concrete Example:
In the sentence 'The chef added <mask1> to the dessert to make it <mask2>', an MDM might simultaneously predict 'sugar' and 'healthier', creating a contradiction. An ILM inserts tokens sequentially (e.g., 'added sugar... to make it sweeter'), preserving coherence.
Key Novelty
Insertion Language Models (ILMs)
- Models the generation process as inserting tokens into a sequence one by one, rather than appending to the end (ARMs) or replacing fixed masks (MDMs)
- Learns a joint distribution over both the vocabulary item to insert AND the position to insert it, allowing the model to dynamically determine sequence length
- Uses a biased denoising objective that trains on normalized counts of dropped tokens between visible tokens, avoiding high-variance Monte Carlo estimates
Architecture
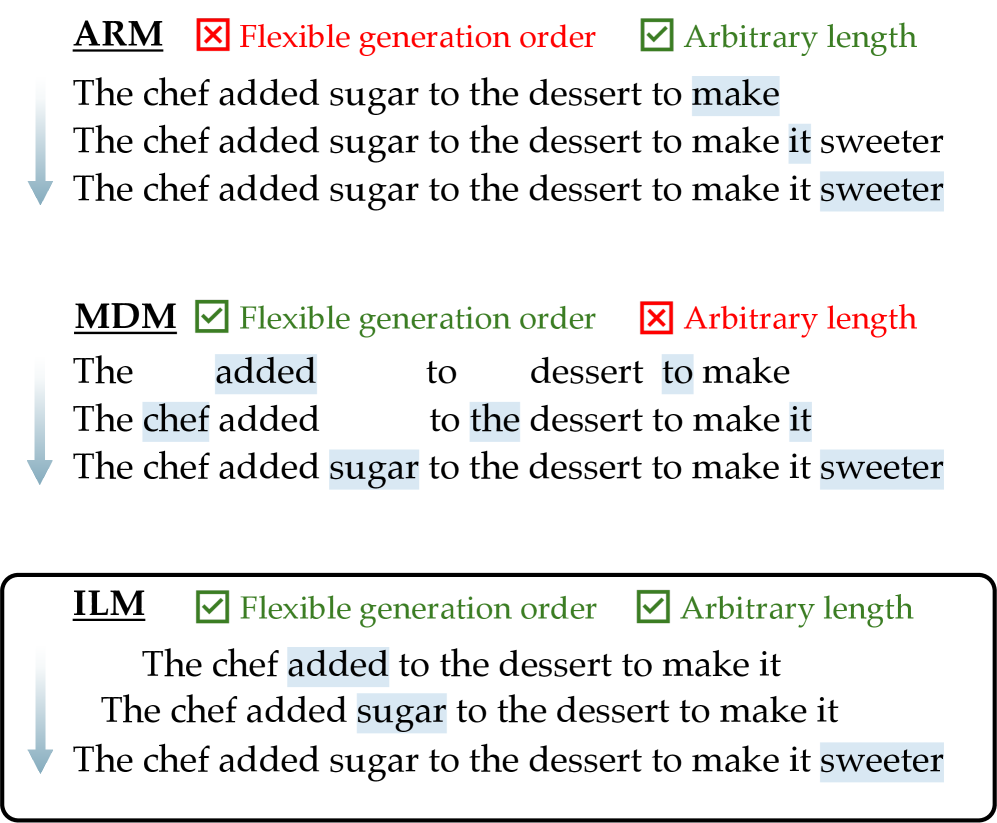
Conceptual comparison of ARM, MDM, and ILM generation processes.
Evaluation Highlights
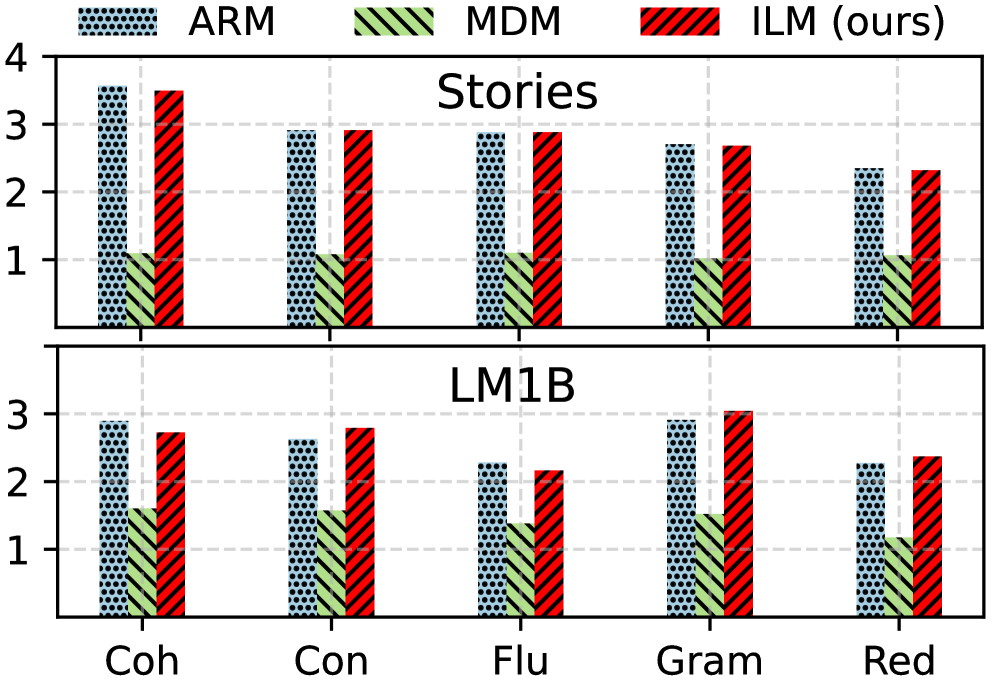
- Achieves 90% sequence accuracy on Zebra Puzzles, significantly outperforming MDMs (55%) and ARMs (40%) on this constraint satisfaction task
- Maintains 100% accuracy on 'Starhard' variable-length path planning graphs, whereas MDMs drop to 21% accuracy due to fixed-length constraints
- Outperforms MDMs on unconditional text generation (LM1B dataset) with lower Perplexity (3.92 vs 4.05) while matching ARMs in linguistic balance
Breakthrough Assessment
8/10
Strongly addresses the limitations of both ARMs (rigid order) and MDMs (fixed length/incoherence) with a novel insertion-based formulation. empirical results on planning and infilling are compelling.