📝 Paper Summary
Multi-turn w. user interactions
Tool-use post-training
Magnet synthesizes high-quality multi-turn tool-use training data by traversing function dependency graphs and applying node operations (Insert, Merge, Split) to simulate complex conversational challenges.
Core Problem
Current LLMs struggle with complex multi-turn function calling interactions, specifically handling nested calls, long-term dependencies, and missing information, due to a lack of high-quality training trajectories.
Why it matters:
- Existing public models achieve only ~10% success rates on complex multi-turn benchmarks compared to nearly 50% for proprietary models.
- Simple back-translation methods for data synthesis fail to capture the structural complexity of real-world multi-turn dialogues (e.g., clarification questions, nested dependencies).
- Training data scarcity limits the ability of open-weights models to bridge the gap with frontier models in agentic tasks.
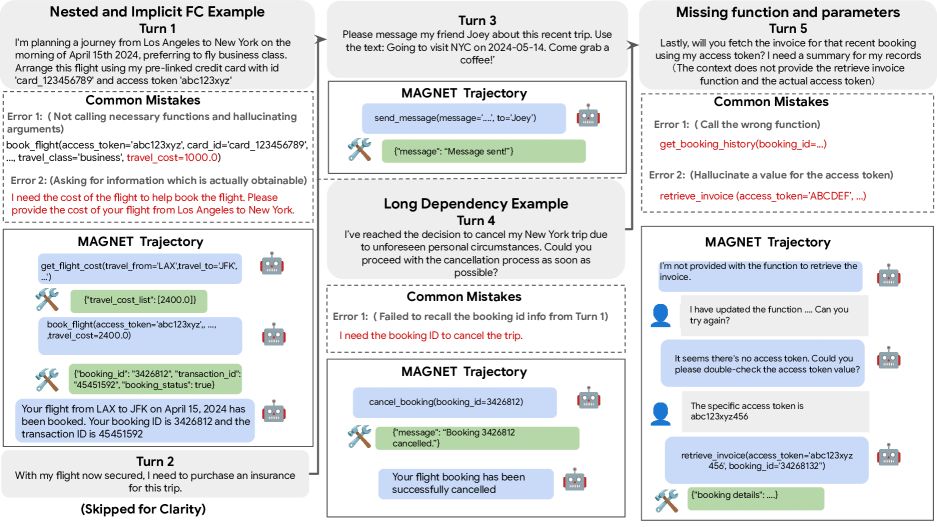
Concrete Example:
A user asks to 'check distance from SF to San Mateo in km'. A standard model might call 'get_distance' returning miles but fail to call 'convert_unit'. Magnet introduces 'Insert' operations to force the generation of nested calls where the second function (conversion) is implicit.
Key Novelty
Graph-based Multi-turn Data Synthesis with Context Distillation
- Models function interactions as a 'local dependency graph' where edges represent input/output dependencies, allowing random walks to form realistic multi-turn function sequences.
- Applies graph node operations (Insert, Merge, Split) to explicitly manufacture difficult scenarios like nested calls, parallel execution, and missing parameters.
- Uses a teacher model to distill reasoning into positive trajectories (via correct hints) and negative trajectories (via misleading hints based on known error patterns) for preference optimization.
Architecture
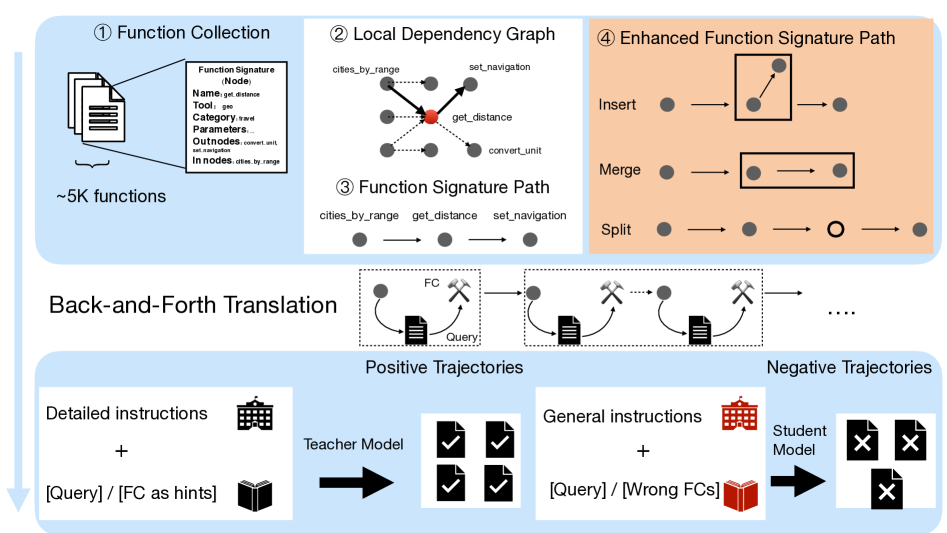
The complete Magnet pipeline: from Graph Construction and Random Walk to Node Operations, Back-and-Forth Translation, and final Trajectory Synthesis/Distillation.
Evaluation Highlights
- Magnet-14B-mDPO achieves 68.01% success rate on the Berkeley Function Calling Leaderboard (BFCL-v3), surpassing its teacher model Gemini-1.5-pro-002 (66.09%).
- +32.5 point improvement over the base Qwen2.5-Coder-14B-Instruct model on BFCL-v3 multi-turn test cases.
- Achieves 73.30% on ToolQuery benchmark, outperforming the teacher model (71.70%) and establishing strong generalization.
Breakthrough Assessment
8/10
Significant methodology for synthetic data generation that pushes open models past proprietary teachers on complex benchmarks. The graph-based construction addresses structural reasoning gaps efficiently.