📝 Paper Summary
Multi-call tool use with flexible plan
RL-based tool use
SWiRL improves LLM performance on complex tasks by generating multi-step tool-use trajectories, filtering them for step-wise soundness, and optimizing the model via reinforcement learning on granular intermediate steps.
Core Problem
Traditional RLHF and RLAIF optimize for single-step responses, failing to address the compounding errors and complex planning required for multi-step reasoning and tool-use tasks.
Why it matters:
- Complex real-world problems require sequences of interrelated actions (searching, synthesizing, calculating), where one early mistake derails the final answer
- Current methods struggle to teach models when to stop searching or how to recover from intermediate errors in long trajectories
- Existing single-step optimization approaches miss the granular feedback needed to correct specific faulty reasoning steps or tool calls
Concrete Example:
In multi-hop QA, a model might incorrectly query a search engine in step 1, retrieve irrelevant info, and hallucinate an answer. Standard outcome-based RL only penalizes the final wrong answer, failing to teach the model *which* specific step (the bad query) caused the failure.
Key Novelty
Step-Wise Reinforcement Learning (SWiRL)
- Decomposes multi-step synthetic trajectories into sub-trajectories, treating each intermediate action (reasoning or tool call) as a distinct training point
- Uses a generative reward model to score the 'reasonableness' of each specific step given its context, rather than just scoring the final outcome
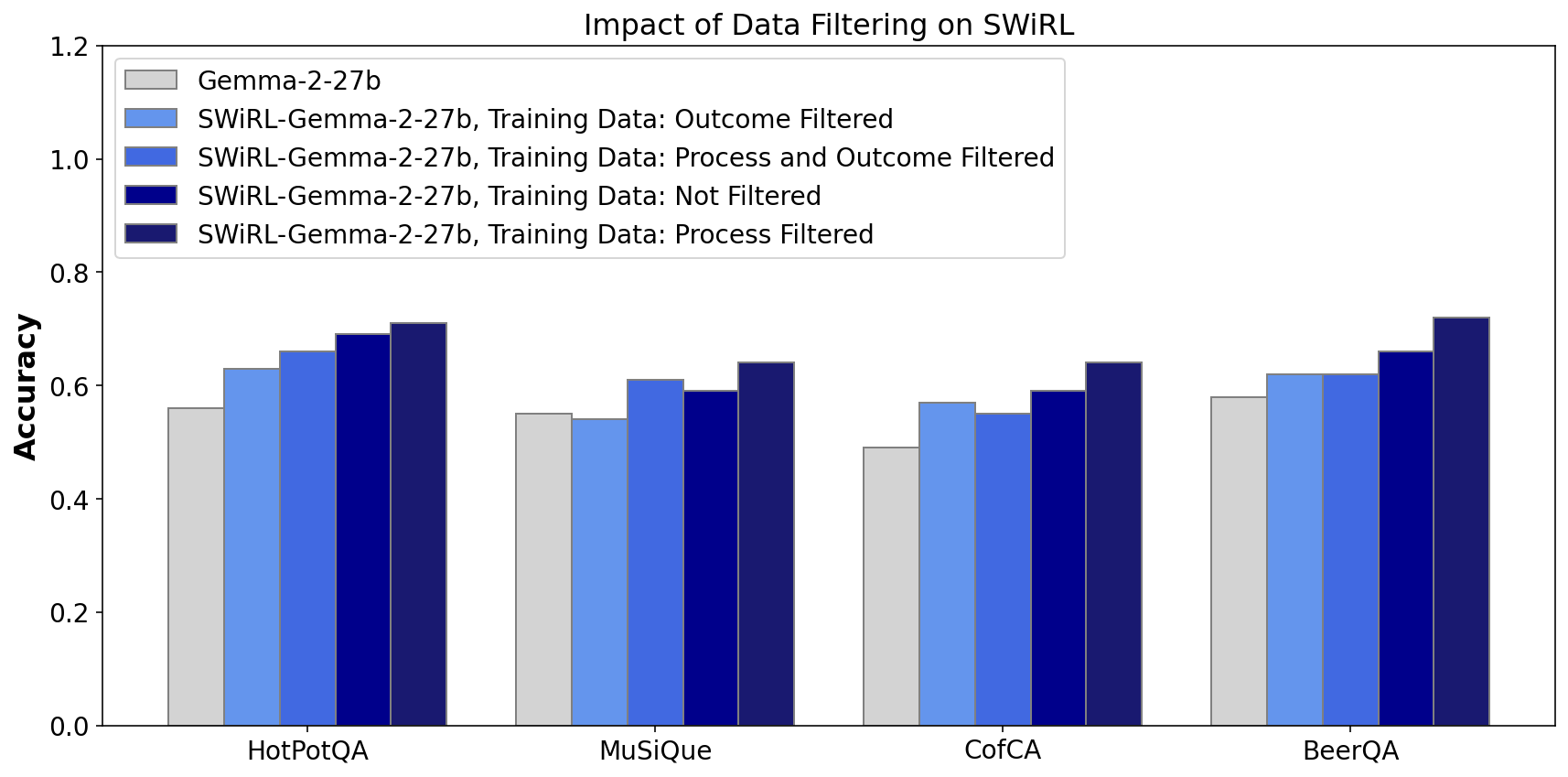
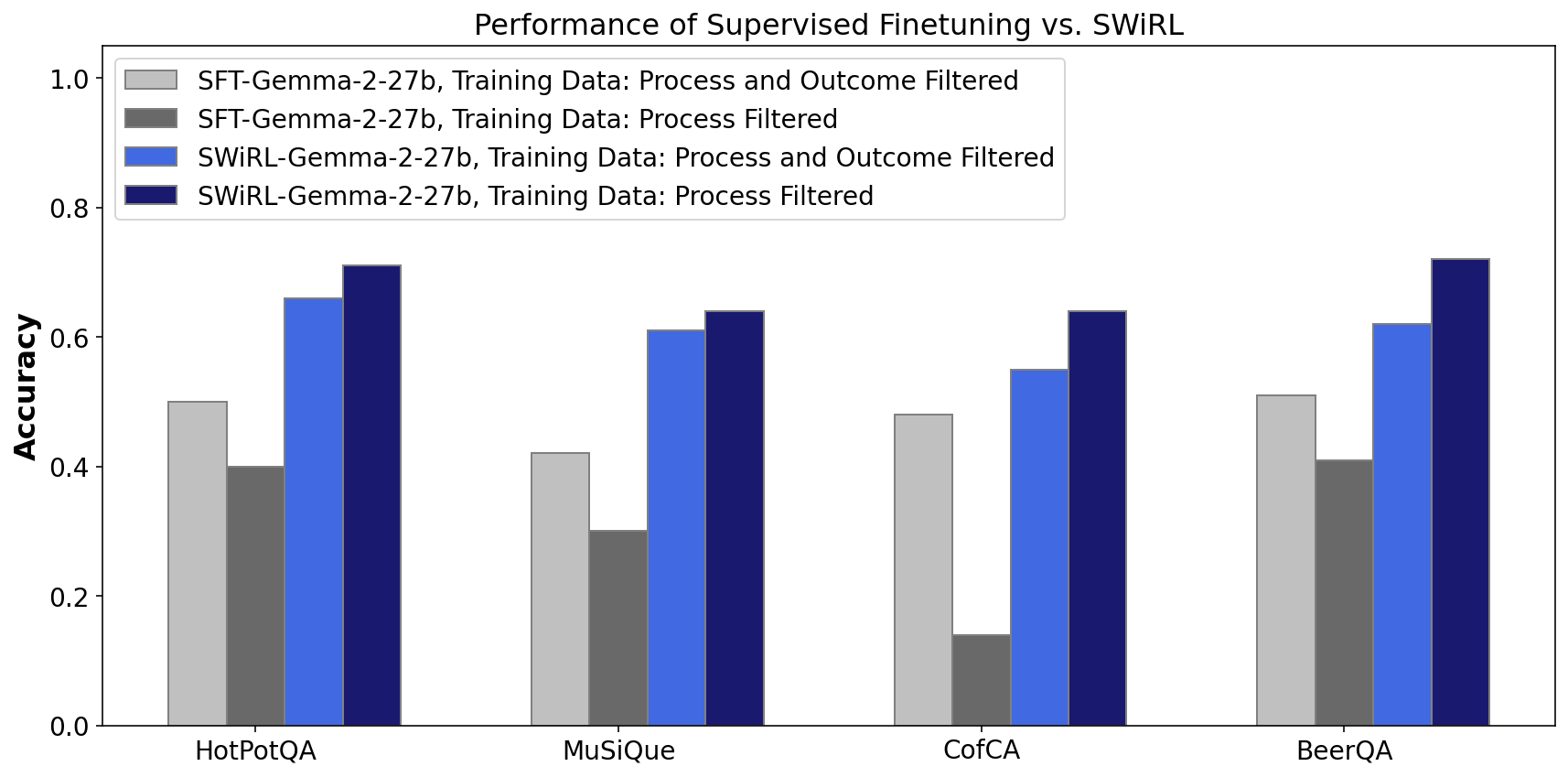
- Demonstrates that filtering data based on step-wise process quality is more effective for RL than filtering solely for correct final answers
Architecture

The Step-Wise Reinforcement Learning (SWiRL) optimization process.
Evaluation Highlights
- +21.5% relative accuracy improvement on GSM8K (math) and +12.3% on HotPotQA (multi-hop QA) compared to baseline approaches
- Training solely on HotPotQA (text QA) improves zero-shot performance on GSM8K (math) by 16.9%, demonstrating strong cross-task generalization
- Outperforms baselines by 15.3% on BeerQA and 11.1% on MuSiQue, confirming effectiveness across diverse multi-hop reasoning datasets
Breakthrough Assessment
8/10
Significant gains in multi-step reasoning and remarkable cross-task generalization (QA to Math). The finding that process-filtered data outperforms outcome-filtered data for RL challenges prevailing assumptions in synthetic data distillation.