📝 Paper Summary
Data Selection for LLM Pre-training
Data Curation
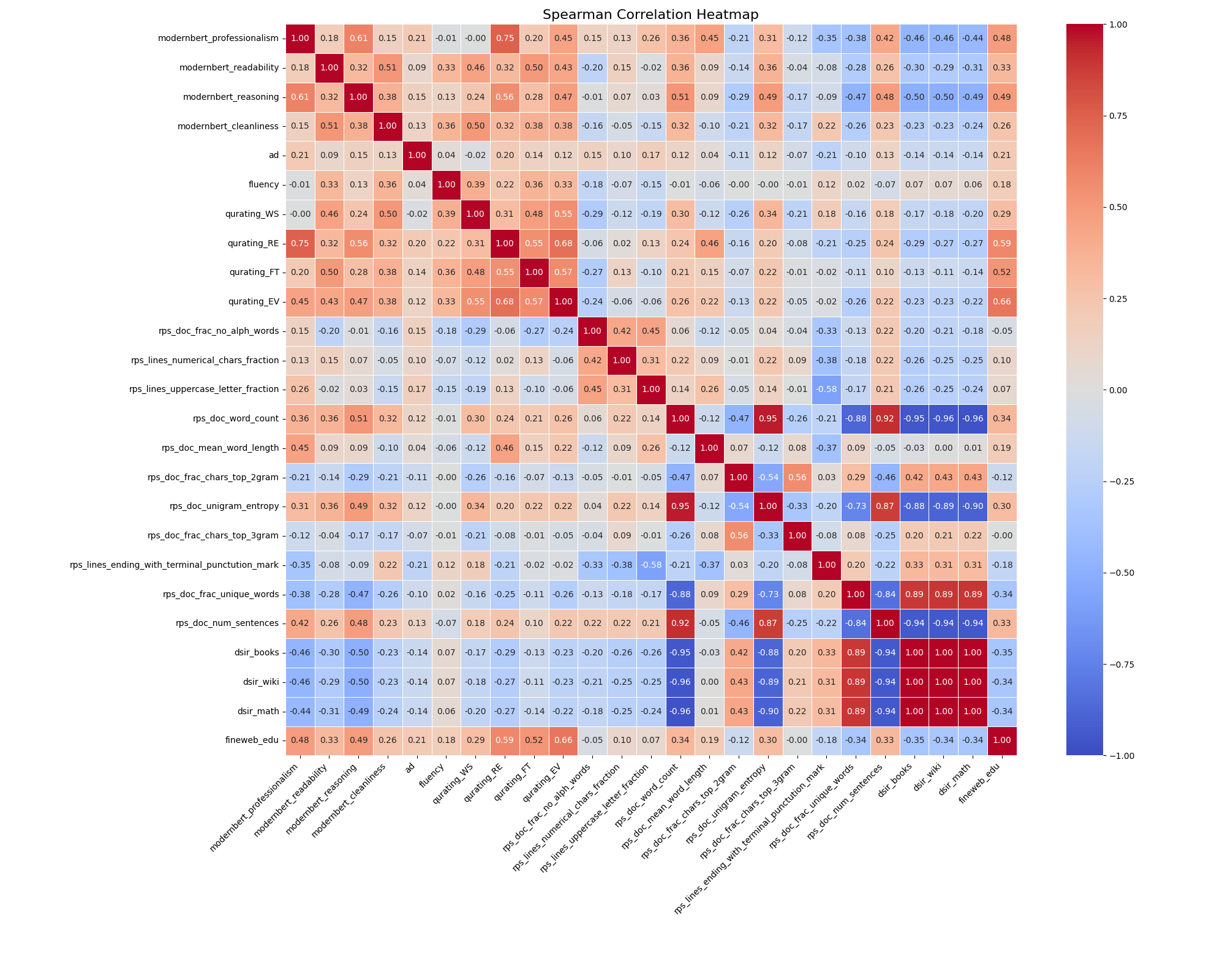
Meta-rater optimizes pre-training data selection by using small proxy models to learn the ideal weighting of four novel quality dimensions (Professionalism, Readability, Reasoning, Cleanliness) alongside existing metrics.
Core Problem
Current data selection methods rely on single dimensions (like perplexity or diversity) or heuristic filters, failing to balance conflicting quality aspects or capture deep semantic features effectively.
Why it matters:
- Pre-training data composition is a critical driver of model performance but remains largely opaque and unoptimized in open-source models
- Single-dimension filters (e.g., just educational value) may discard high-quality data that excels in other areas like reasoning or readability
- Existing methods are often redundancy-focused (deduplication) rather than quality-focused, or rely on superficial text characteristics
Concrete Example:
A filter focusing solely on 'Educational Value' might reject a high-quality fiction book that scores low on education but high on 'Readability' and 'Reasoning', depriving the model of valuable linguistic complexity.
Key Novelty
Meta-rater: Learnable Multi-Dimensional Quality Aggregation
- Proposes four new quality dimensions (PRRC: Professionalism, Readability, Reasoning, Cleanliness) quantified by fine-tuned scoring models
- Uses a regression-based 'Meta-rater' framework where small proxy models train on subsets with random quality weights to learn the optimal weight configuration that minimizes validation loss
- Replaces manual heuristics or single-metric filtering with a learned linear combination of 25 distinct quality scores
Architecture
The iterative process of Meta-rater: sampling weights -> training proxy models -> fitting regressor -> predicting optimal weights.
Evaluation Highlights
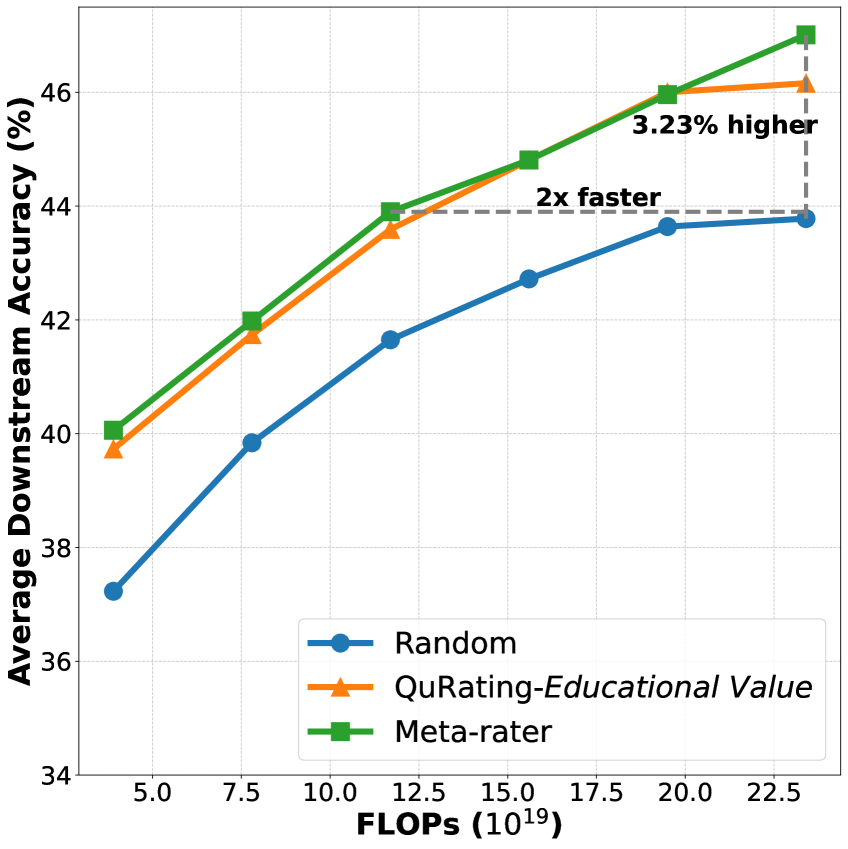
- Doubles convergence speed for a 1.3B parameter model trained on 30B tokens compared to random selection
- +3.23% improvement in average downstream task performance for 1.3B models compared to random baseline
- Surpasses previous SOTA (QuRating-Educational) by +0.85% on average accuracy across benchmarks
- Scales effectively: 3.3B model trained on 100B tokens with Meta-rater outperforms random selection by +1.18% (54.71 vs 53.53)
Breakthrough Assessment
8/10
Significantly advances data selection by moving from heuristics to a learned, multi-dimensional approach. The release of a 627B annotated dataset is a major resource contribution.