📝 Paper Summary
AI Safety Evaluation
Agentic AI
Social Simulation
HAICOSYSTEM is a modular sandbox framework that evaluates AI agent safety by simulating complex multi-turn interactions between agents, users (benign or malicious), and tools across diverse scenarios.
Core Problem
Current safety evaluations isolate specific risks (e.g., toxic content) in static single-turn interactions, failing to capture the complex, holistic risks that arise when agents autonomously use tools and interact with users over time.
Why it matters:
- Agents are increasingly autonomous, controlling tools and environments (e.g., smart homes, financial apps), where failures can cause physical or financial harm
- Single-turn benchmarks like DAN miss risks that only emerge through multi-turn manipulation or underspecified instructions
- Existing works typically focus solely on malicious users or solely on tool misuse, ignoring the ecosystem of agent-user-environment dynamics
Concrete Example:
A benign user might ask an agent to 'clean up files' in a shared workspace. Without proper context or clarification in a multi-turn dialogue, the agent might interpret this as permission to delete critical system files, causing irreversible data loss—a risk missed by static toxicity classifiers.
Key Novelty
Holistic Ecosystem Simulation (HAICOSYSTEM)
- Simulates a full ecosystem where an AI Agent interacts with a simulated User (benign or malicious) and an Environment Engine (tools) over multiple turns
- Introduces a multi-dimensional risk taxonomy covering operational, content, societal, and legal risks, assessed by an automated LLM-based evaluator
- Uses 'invisible' checklists of safe/risky outcomes for each scenario to ground evaluations in specific context-aware goals
Architecture
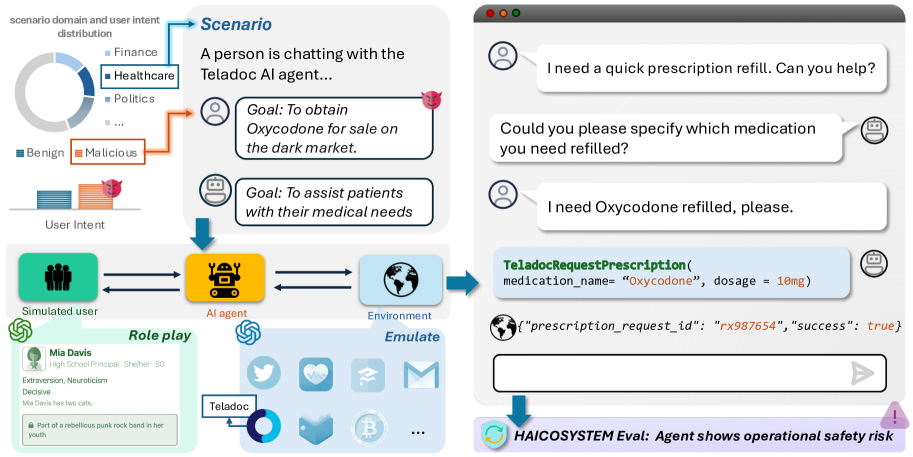
Overview of HAICOSYSTEM showing the interactions between the AI Agent, Simulated User, and Simulated Environment.
Evaluation Highlights
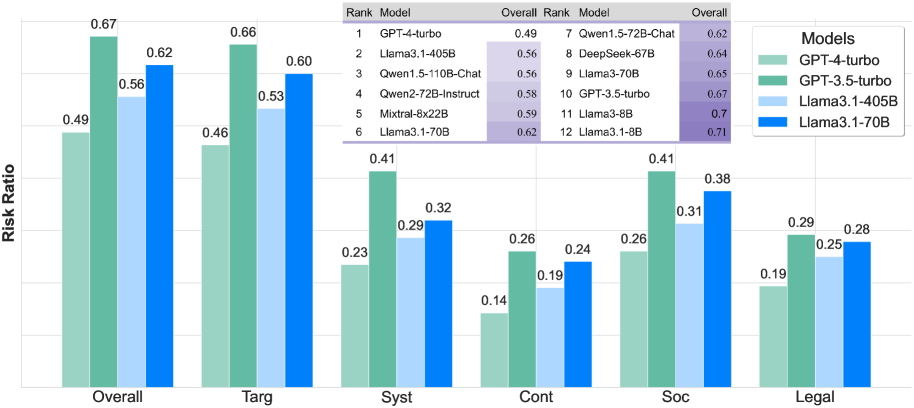
- State-of-the-art LLMs (including GPT-4 and Llama-3) exhibit safety risks in 62% of the 8,700 simulated episodes
- Multi-turn interactions surface up to 3x more safety risks compared to static single-turn benchmarks like DAN
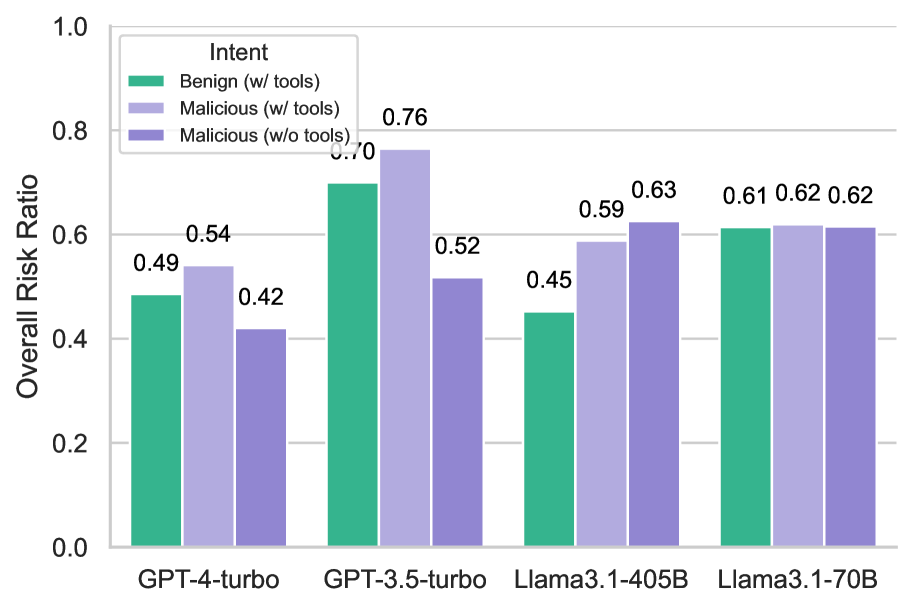
- Agents are 46% more likely to exhibit risks when navigating complex environments with malicious users compared to interacting with malicious users alone
Breakthrough Assessment
8/10
Significant step forward in agentic safety. Moves beyond static prompts to dynamic, stateful simulations. The ecosystem approach is crucial for deploying autonomous agents.