📝 Paper Summary
Agentic AI
Autonomous Software Engineering
AutoDev is a framework that enables autonomous AI agents to execute complex software engineering tasks by interacting directly with a secure IDE environment to edit files, run builds, and execute tests.
Core Problem
Existing AI coding assistants (like Copilot) are limited to chat-based suggestions and lack the ability to autonomously execute IDE actions like building, testing, or linting to validate their own code.
Why it matters:
- Developers still must manually copy-paste code, fix syntax errors, run tests, and interpret logs, reducing the actual automation benefit.
- Chat-based assistants lack deep contextual awareness of the repository state (e.g., build failures or test results) needed for iterative debugging.
- Current tools cannot autonomously loop through 'edit-compile-test' cycles to resolve complex tasks without human intervention.
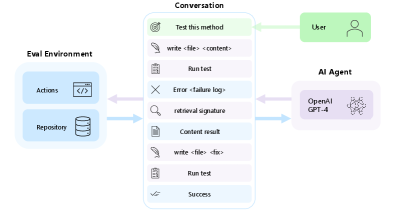
Concrete Example:
A user asks an AI to 'test a specific method.' A standard assistant suggests code snippets. AutoDev, however, writes the test file, runs `pytest`, reads the failure log, edits the code to fix the bug, and re-runs the test until it passes—all without user input.
Key Novelty
Autonomous IDE-Native Agents
- Empowers agents with a comprehensive library of IDE tools (build, test, git, lint) executed within a secure Docker container, moving beyond simple text generation.
- Orchestrates a loop where agents perceive compiler/test feedback directly and iteratively repair their own work.
- Enforces granular security policies (Guardrails) to restrict what commands agents can execute (e.g., allowing local commits but blocking push operations).
Architecture
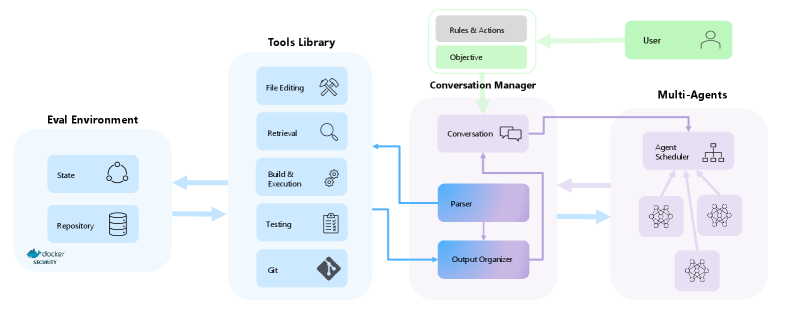
The AutoDev architecture, detailing the interaction between the Conversation Manager, Agent Scheduler, Tools Library, and Evaluation Environment.
Evaluation Highlights
- Achieves 91.5% Pass@1 on HumanEval code generation, effectively solving problems by validating them against tests autonomously.
- Achieves 87.8% Pass@1 on HumanEval test generation, creating valid test cases that pass and invoke the focal method.
- Demonstrates fully autonomous workflow including file editing, test execution, and iterative repair without human-in-the-loop.
Breakthrough Assessment
8/10
Significant step forward from 'chatbots' to 'agents' in SE. The deep integration of execution feedback (build/test logs) into the agent's context loop is a major enabler for autonomy.