📝 Paper Summary
Agent evaluation and benchmarking
Cost-aware agent design
Current AI agent benchmarks incentivize needless complexity and cost; this paper proposes evaluating agents on accuracy-cost Pareto frontiers and proves simple baselines often outperform complex architectures when cost-controlled.
Core Problem
Agent benchmarks focus narrowly on accuracy, ignoring cost and reproducibility, leading to over-engineered 'state-of-the-art' agents that are actually just expensive retry loops.
Why it matters:
- Researchers mistakenly attribute gains to complex 'System 2' planning when they are essentially just retrying stochastic models
- Downstream developers cannot identify efficient agents because benchmarks conflate model capabilities with agent architecture costs
- Lack of holdout sets allows agents to overfit via shortcuts, making them fragile in real-world deployment
Concrete Example:
On the HumanEval benchmark, complex agents like LATS and Reflexion claim SOTA status, but a simple 'Warming' baseline (retrying with increasing temperature) matches their accuracy while costing significantly less (LATS costs >50x more).
Key Novelty
Cost-controlled Agent Evaluation & Joint Optimization
- Introduce simple, cost-effective baselines (Retry, Warming, Escalation) that rival complex agent architectures
- Evaluate agents on a 2D Pareto frontier of accuracy vs. cost, rather than a single accuracy leaderboard
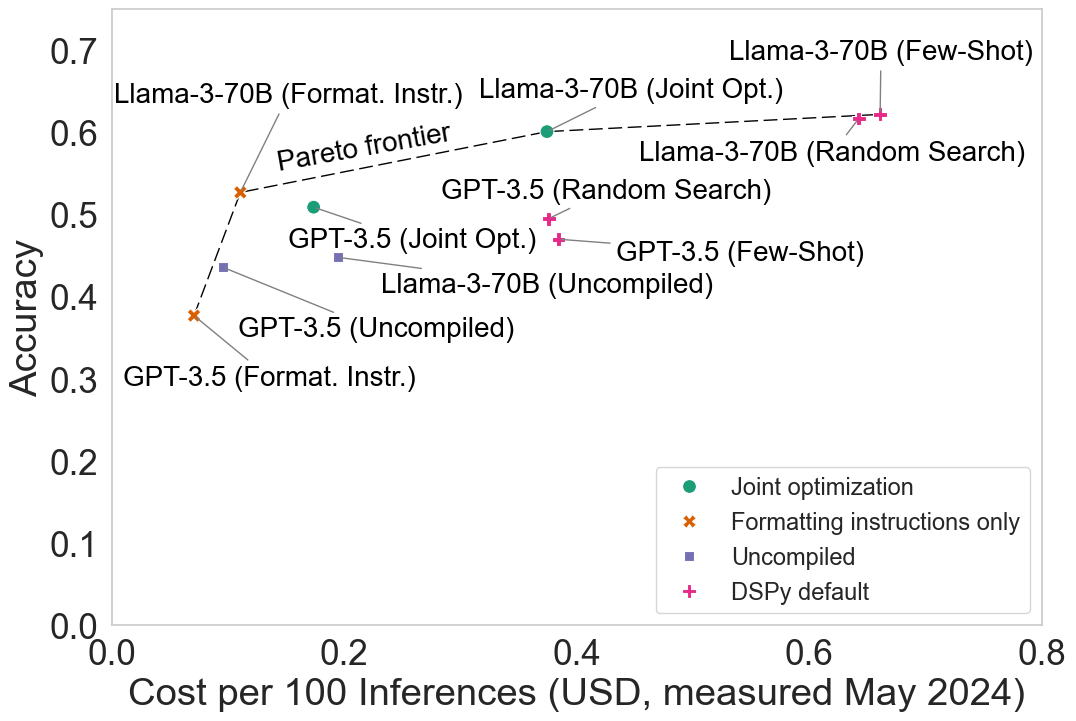
- Demonstrate 'joint optimization' of agent parameters (prompts, few-shot examples) to minimize variable inference costs while maintaining accuracy
Architecture
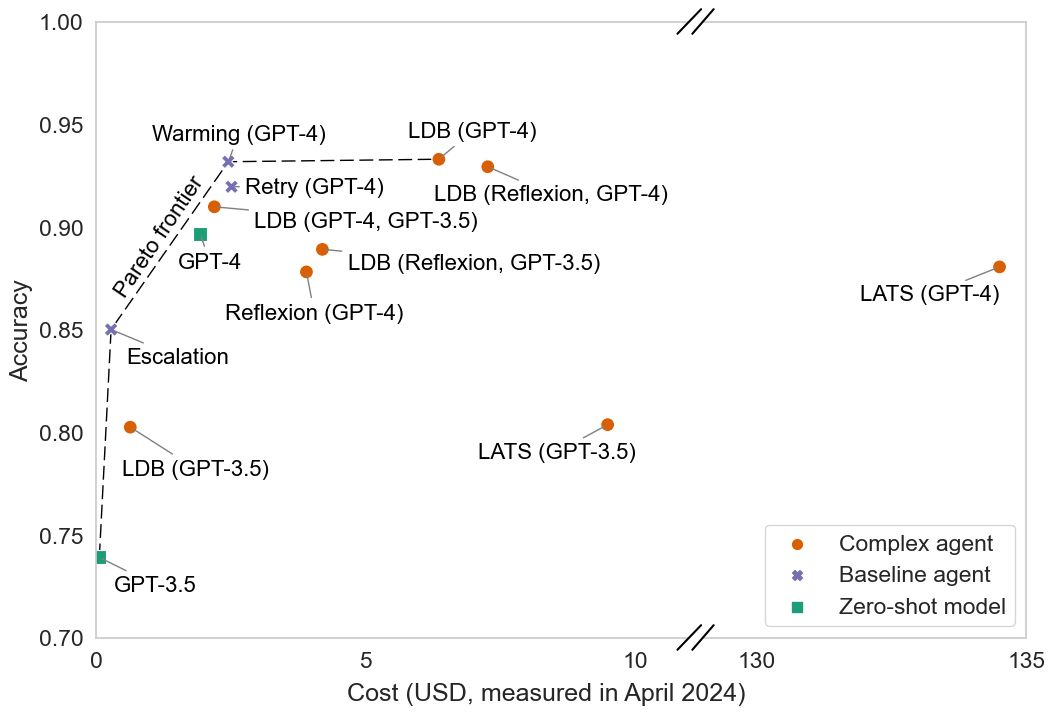
A scatter plot (Pareto curve) comparing Accuracy (y-axis) vs. Cost (x-axis, log scale) for various agents on HumanEval.
Evaluation Highlights
- Simple 'Warming' strategy (gradually increasing temperature) matches SOTA agent 'Reflexion' on HumanEval (91% vs 91%) while costing ~30% less
- Simple 'Escalation' strategy achieves 86.6% accuracy on HumanEval at <50% of the cost of LDB (GPT-3.5)
- Joint optimization on HotPotQA reduces variable cost by 53% for GPT-3.5 and 41% for Llama-3-70B while maintaining accuracy compared to default DSPy agents
Breakthrough Assessment
9/10
Critically exposes the 'emperor has no clothes' problem in agent research: complex architectures are often just expensive wrappers. The proposed Pareto evaluation standard is a necessary correction for the field.