📝 Paper Summary
Self-evolving Agentic reasoning
Automated Machine Learning (AutoML)
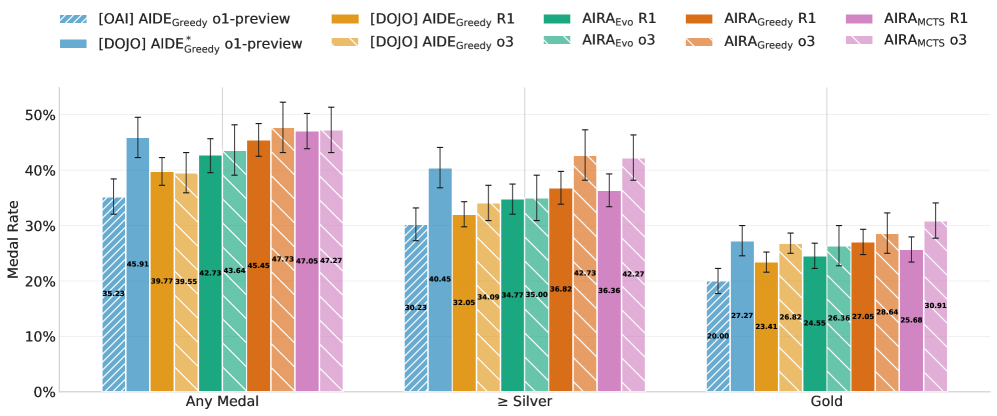
By decoupling search algorithms from code-modification operators, this work identifies operator quality as the primary bottleneck and achieves state-of-the-art results on MLE-bench using enhanced operators and evolutionary search.
Core Problem
Current research agents entangle search logic, code operators, and compute resources, making it difficult to identify why they fail or how to systematically improve them.
Why it matters:
- Entangled designs prevent controlled experiments, obscuring whether gains come from better planning, better coding tools, or simply more compute
- Existing agents like AIDE often fail to recover from bugs or explore diverse solutions because they rely on simple greedy search with limited operator sets
- The 'generalization gap' in automated ML engineering leads agents to overfit to validation metrics, selecting solutions that perform poorly on held-out test sets
Concrete Example:
In a Kaggle competition task, an agent might greedily optimize validation loss using a 'Debug' operator on a single script path. It eventually gets stuck in a local optimum or a bug loop. A better approach would maintain a population of diverse scripts and 'Crossover' successful features from different distinct solutions.
Key Novelty
Graph-Based Search Framework for AI Research Agents (AIRA)
- Formalizes agents as a tuple of (Search Policy, Operator Set, Fitness Function), allowing distinct upgrades to search (e.g., MCTS vs. Evolutionary) separate from code manipulation tools
- Introduces 'AIRA-dojo', a scalable execution environment that ensures reproducibility by isolating agents in containers with strict compute/time quotas
- Demonstrates that improving operators (adding 'Crossover') yields larger gains than changing search algorithms, unlike prior assumptions focusing heavily on planning
Architecture
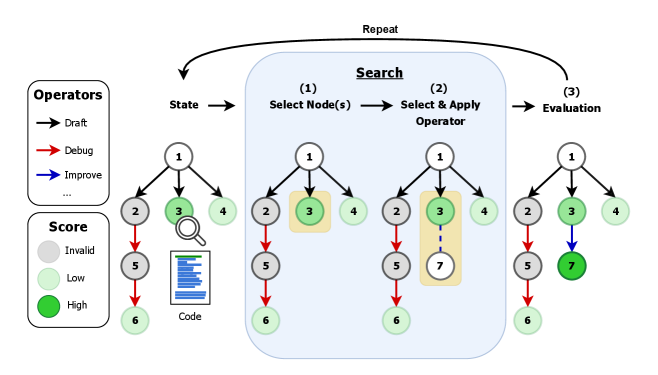
The conceptual framework of an AI research agent as a search process over a graph of artifacts.
Evaluation Highlights
- Increases Kaggle medal success rate on MLE-bench lite from 39.6% (AIDE baseline) to 47.7% using best search-operator pairing
- Further improves performance to 55% medal rate on MLE-Bench Lite when using the latest version of the AIRA-dojo framework
- Identifies a 9-13% potential gain in medal rate if agents could select solutions based on test scores rather than validation scores, quantifying the generalization gap
Breakthrough Assessment
8/10
Significantly advances automated ML by rigorously decoupling search from operators, providing a scalable open-source framework (AIRA-dojo), and achieving SOTA on a challenging benchmark.