📝 Paper Summary
AI Agent Security
LLM Vulnerabilities
Protocol Security
This survey introduces a unified threat model for LLM-agent ecosystems, cataloging over thirty attack techniques spanning input manipulation, model compromise, system privacy, and emerging protocol-level vulnerabilities.
Core Problem
The rapid integration of LLMs with plugins and inter-agent protocols (like MCP) has outpaced security practices, creating brittle integrations with weak validation that are vulnerable to attacks ranging from prompt injections to protocol exploits.
Why it matters:
- Current workflows rely on ad-hoc authentication and inconsistent schemas, making them prone to exploitation
- Prior research is fragmented, focusing on isolated exploits rather than the full communication stack including new protocols like MCP
- High success rates of existing attacks (e.g., >90% for jailbreaks) threaten the reliability of autonomous agent deployments
Concrete Example:
A malicious user executes a Prompt-to-SQL (P2SQL) injection where a natural language query bypasses validation to execute unauthorized database commands, or a 'Toxic Agent Flow' exploit in a GitHub MCP server corrupts the agent's context.
Key Novelty
Unified End-to-End Threat Model for LLM-Agents
- Bridges the gap between input-level exploits (prompts) and protocol-layer vulnerabilities (MCP, A2A) in a single taxonomy
- Provides formal mathematical formulations for threat models across four categories: Input Manipulation, Model Compromise, System & Privacy, and Protocol Vulnerabilities
- Analyzes specific risks in emerging standards like the Model Context Protocol (MCP) which were previously underexplored
Architecture
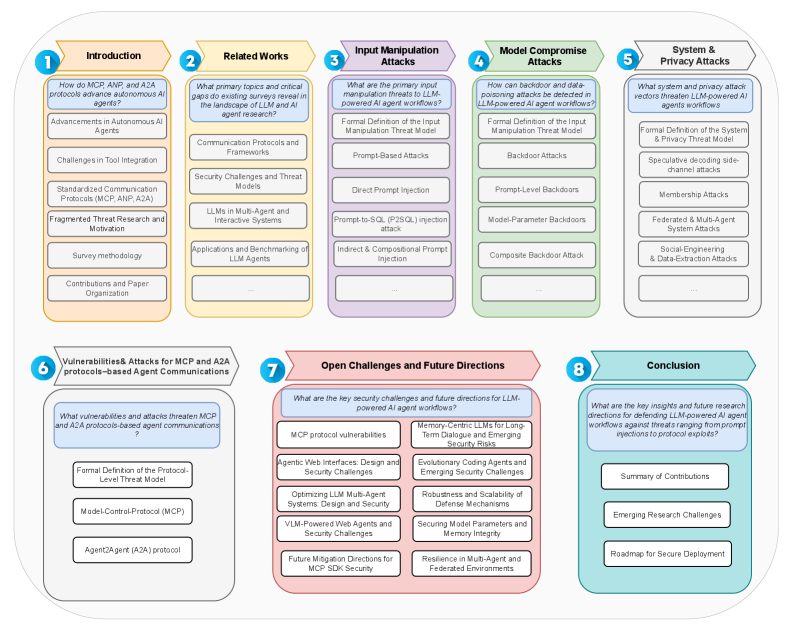
Organization of the survey paper, mapping the four main threat categories to specific sections.
Evaluation Highlights
- Cataloged over 30 distinct attack techniques verified against real-world incidents and vulnerability databases (CVE, NIST NVD)
- Highlighted attack success rates from literature: >90% for sophisticated jailbreaks (e.g., GPTFuzz) and near-perfect success for backdoor implants like DemonAgent
- Identified critical vulnerabilities in the host-to-tool and agent-to-agent layers of the Model Context Protocol (MCP)
Breakthrough Assessment
8/10
Comprehensive synthesis of the fragmented agent security landscape. The inclusion of formal definitions and specific focus on new protocols like MCP distinguishes it from general LLM security surveys.