📝 Paper Summary
Embodied AI
Robot Learning
Vision-Language-Action Models (VLAs)
This survey establishes a comprehensive taxonomy for Vision-Language-Action (VLA) models, categorizing them into components, low-level control policies, and high-level task planners to guide future embodied AI research.
Core Problem
The rapid emergence of VLA models—which integrate vision, language, and action for robotics—lacks a unified definition and structural organization, making it difficult to track progress across disparate methods.
Why it matters:
- Traditional robot policies (RL-based) are limited to narrow tasks in controlled environments, whereas VLAs promise generalizable, open-world manipulation
- The field is evolving quickly with distinct approaches for low-level control vs. high-level planning, creating a need for a clear hierarchical framework to understand how these components interact
Concrete Example:
A traditional RL policy might learn to grasp a specific bottle but fail if asked to 'pick up the blue object' in a new room. A VLA addresses this by grounding language instructions ('blue object') in visual data to generate precise motor actions, but existing literature scatters these contributions across CV, NLP, and Robotics venues.
Key Novelty
Hierarchical Taxonomy of VLAs
- Defines VLA broadly as any model mapping vision+language to robot actions, differentiating 'Large VLAs' (based on LLMs) from general architectures
- Organizes the field into three pillars: individual components (representation, dynamics), low-level control policies (mapping perception to motor commands), and high-level task planners (decomposing long-horizon goals)
- Integrates recent advances in world models and chain-of-thought reasoning into the embodied context
Architecture
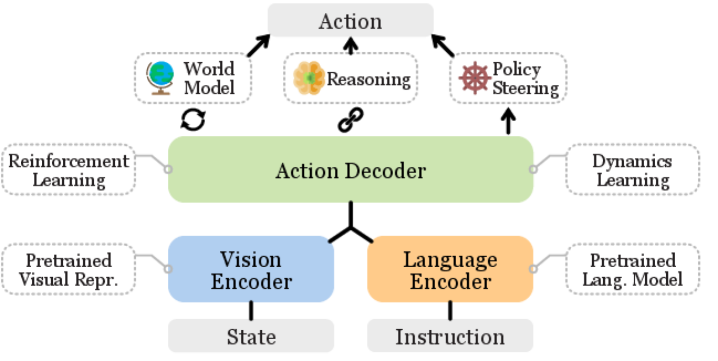
A generic architecture for Vision-Language-Action Models (VLAs)
Evaluation Highlights
- Categorizes over 50 specific models (e.g., RT-1, Gato, VoxPoser) into distinct architectural families
- Summarizes key resources including datasets like Open X-Embodiment and simulators like Habitat and Maniskill
- Identifies critical gaps in current VLA research, such as the need for 3D spatial reasoning and safety guarantees in real-world deployment
Breakthrough Assessment
7/10
A timely and necessary systematization of a chaotic, high-impact field. While it is a survey and does not propose a new model, its taxonomy is likely to become a standard reference for future work.