📊 Experiments & Results
Evaluation Setup
Comprehensive evaluation across medical VQA, image classification, report generation, and text-only medical QA
Benchmarks:
- VQA-RAD (Radiology Visual Question Answering)
- SLAKE (Bilingual Medical VQA)
- MIMIC-CXR (Chest X-ray Report Generation & Classification)
- MedQA (USMLE) (Medical Question Answering (Text))
- AgentClinic (Agentic Medical Diagnosis)
Metrics:
- Accuracy
- F1 Score
- RadGraph F1 (for report generation)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| MedGemma 4B demonstrates strong performance on Visual Question Answering, outperforming larger models. | ||||
| VQA-RAD | Accuracy (Open) | 78.4 | 83.0 | +4.6 |
| SLAKE | Accuracy (Open) | 88.6 | 91.3 | +2.7 |
| Text-only benchmarks show MedGemma 27B is competitive with state-of-the-art open models. | ||||
| MedQA (USMLE) | Accuracy | 88.6 | 84.9 | -3.7 |
| Agentic evaluation shows significant improvements over base models. | ||||
| AgentClinic-MedQA | Success Rate | 47.4 | 58.2 | +10.8 |
Experiment Figures
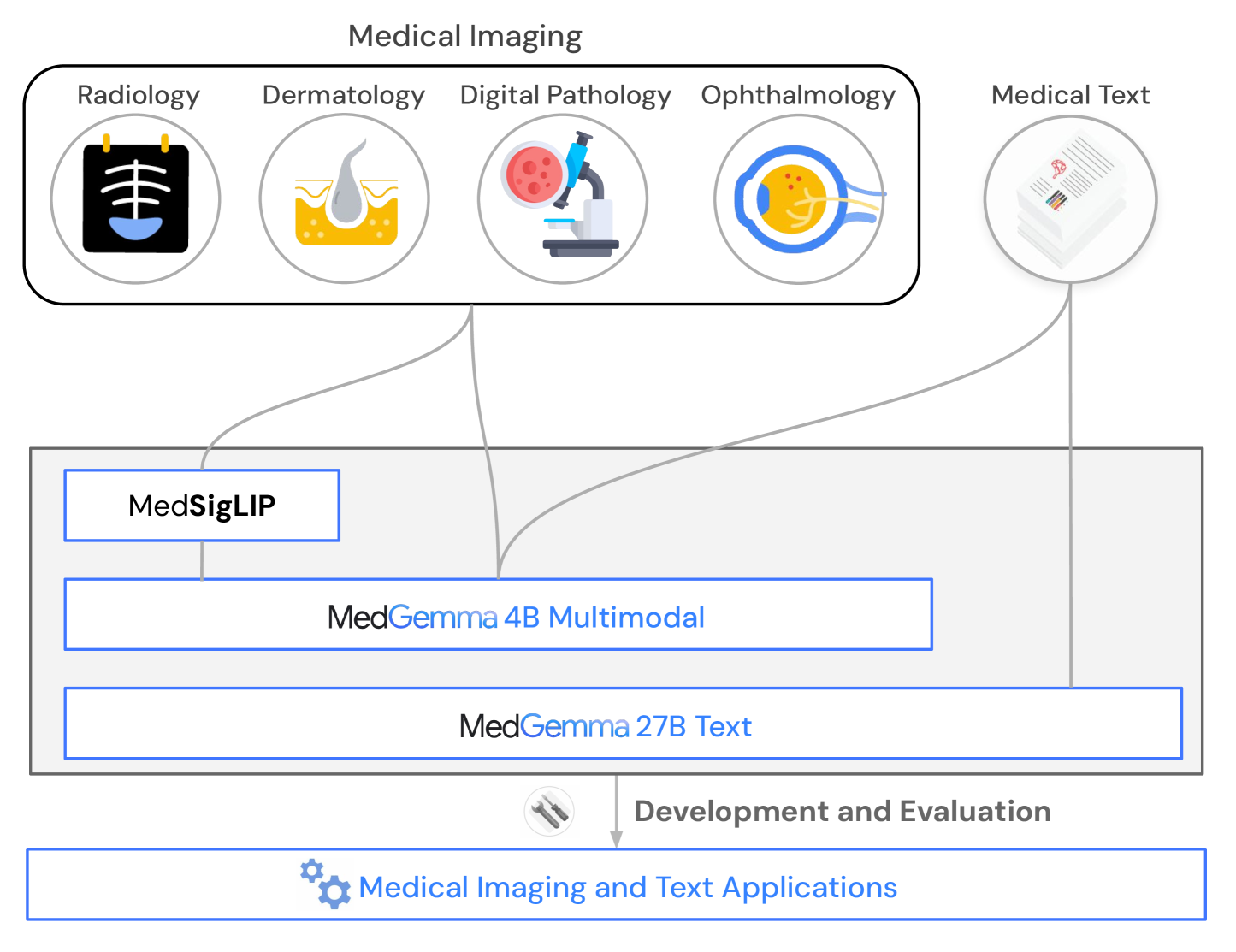
Overview of the MedGemma collection, including the 4B multimodal model, 27B text model, and MedSigLIP encoder.
Main Takeaways
- MedGemma 4B achieves SOTA-level performance on radiology VQA tasks, surpassing much larger proprietary models like Med-Gemini 2D.
- Fine-tuning the vision encoder (MedSigLIP) specifically for medical domains yields significant gains in visual understanding compared to general-purpose encoders.
- The models maintain strong general-purpose capabilities while improving drastically on medical reasoning, validating the effectiveness of the specialized post-training recipe.
- Fine-tuning MedGemma on subdomains (like EHR retrieval or Histopathology) further boosts performance, showing the model's value as a foundation for downstream adaptation.