📝 Paper Summary
Software Engineering Agents
Multi-Agent Systems
MASAI decomposes complex software engineering tasks into sub-problems handled by specialized sub-agents (reproducers, localizers, fixers) that employ different strategies to achieve state-of-the-art bug resolution.
Core Problem
Solving repository-scale software issues requires diverse skills (testing, localization, coding) that overwhelm single-agent architectures trying to maintain a single context window.
Why it matters:
- Single strategies (like ReAct) struggle to generalize across the distinct phases of bug fixing (e.g., searching vs. patching).
- Long reasoning trajectories in single agents inflate costs and fill context windows with irrelevant information, degrading performance.
- Existing methods often fail to rigorously verify fixes because they lack dedicated sub-processes for reproducing issues via test cases.
Concrete Example:
When fixing a bug in a large repo like Django, a single agent might get lost navigating hundreds of files. It might find the bug but fail to write a reproduction test, leading to a 'fix' that introduces new errors or doesn't actually solve the reported issue.
Key Novelty
Modular Strategy-Specific Sub-Agents
- Instantiates distinct sub-agents for specific phases (Test Generation, Reproduction, Localization, Fixing, Ranking), each with optimized strategies (ReAct vs. CoT).
- Uses a 'lazy representation' for code retrieval to keep context concise, returning only signatures for files/classes and full bodies only for functions.
- Decouples the 'Fixer' (which generates multiple patches) from the 'Ranker' (which validates them against a generated reproduction test).
Architecture

The 5-stage pipeline of MASAI illustrating the flow of information between sub-agents.
Evaluation Highlights
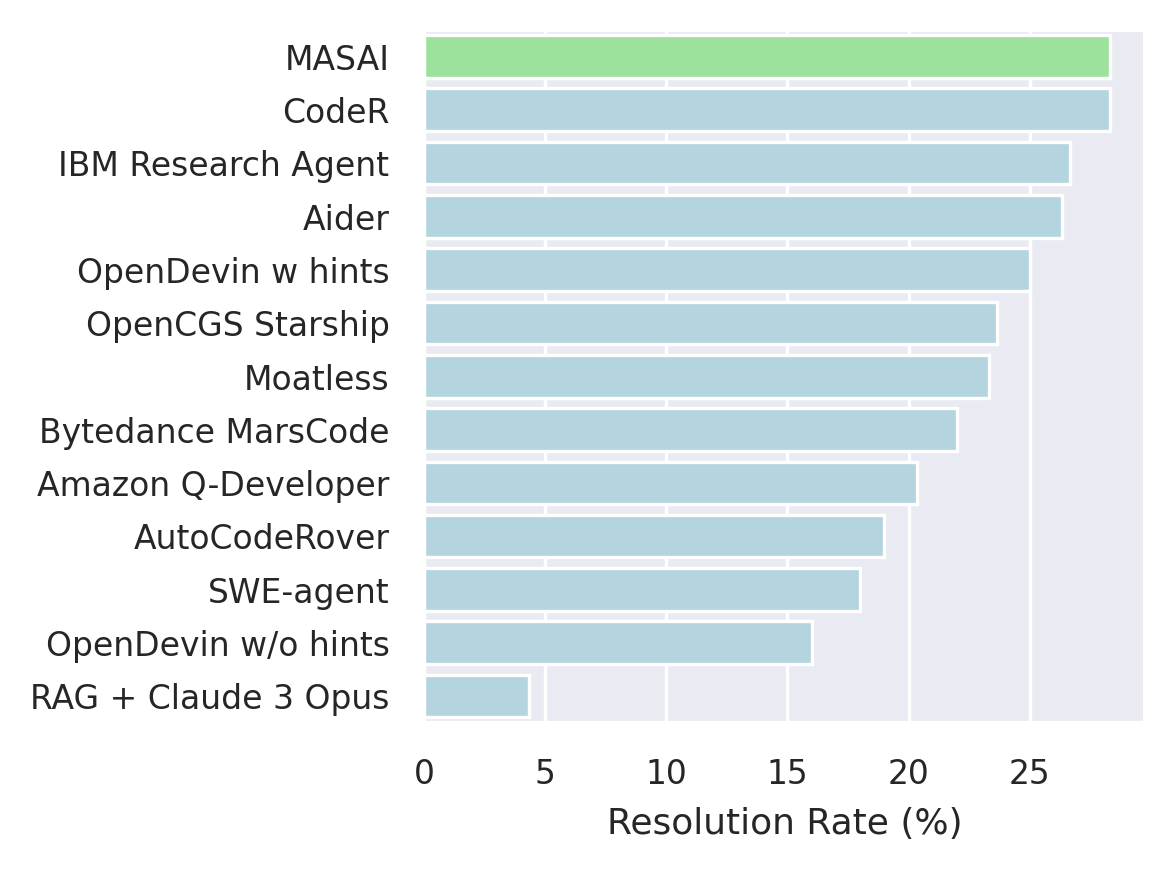
- Achieves 28.33% resolution rate on SWE-bench Lite, the highest among reported methods at the time of publication.
- Outperforms SWE-agent (18.00%) and AutoCodeRover (22.67%) on the same benchmark.
- Demonstrates high cost-efficiency with an average per-issue cost of $1.96 USD.
Breakthrough Assessment
8/10
Significant improvement over SOTA on a very difficult benchmark (SWE-bench Lite). The modular design provides a clear blueprint for future engineering agents, though it relies heavily on the strength of the underlying model (GPT-4o).