📝 Paper Summary
Interactive 3D Scene Synthesis
Embodied AI Environments
Neuro-symbolic 3D Generation
Scenethesis is a training-free framework that combines LLM reasoning for coarse planning with vision foundation models for spatial guidance and physics-based optimization to generate realistic, interactive 3D scenes.
Core Problem
Existing methods for text-to-3D scene generation either rely on small-scale datasets (limiting diversity) or use LLMs that lack spatial perception, resulting in unnatural layouts and physical violations.
Why it matters:
- Current LLM-generated scenes often have floating objects or collisions, making them unusable for embodied AI simulation or gaming
- Learning-based methods are constrained to indoor datasets like 3D-FRONT, failing to generalize to outdoor environments or novel object combinations
- Manual design is unscalable, while procedural generation yields overly simplistic scenes lacking real-world functional relationships
Concrete Example:
When an LLM attempts to generate a room, it might place chairs facing a cabinet instead of a table, or place a cabinet against a window (blocking it). Small objects might be restricted to tops of cabinets rather than inside shelves, or objects might interpenetrate.
Key Novelty
Vision-Perception Bridging for LLM Scene Planning
- Uses 2D image generation models as a spatial prior to 'show' the LLM where objects should go, rather than relying solely on text-based spatial reasoning
- Employs a novel optimization process that treats 3D layout generation as alignment between retrieved 3D assets and 2D visual guidance, enforced by semantic correspondence
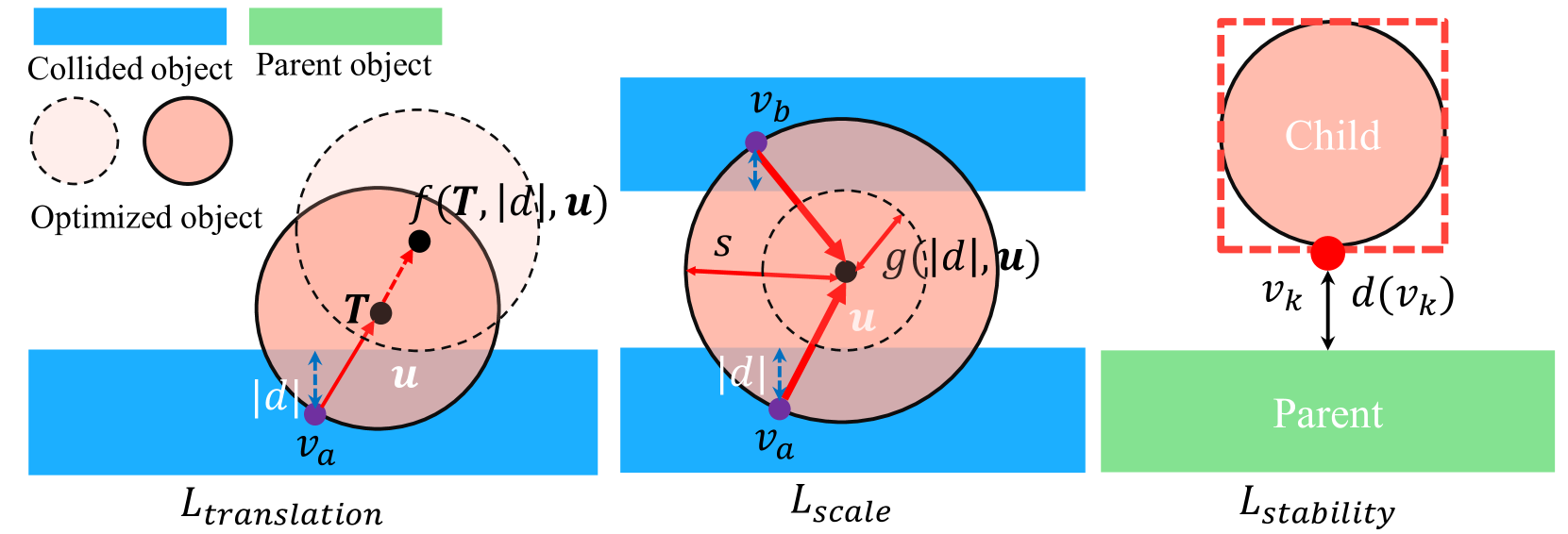
- Replaces standard bounding boxes with Signed Distance Fields (SDFs) for collision detection, allowing complex interactions like placing objects inside shelves
Architecture
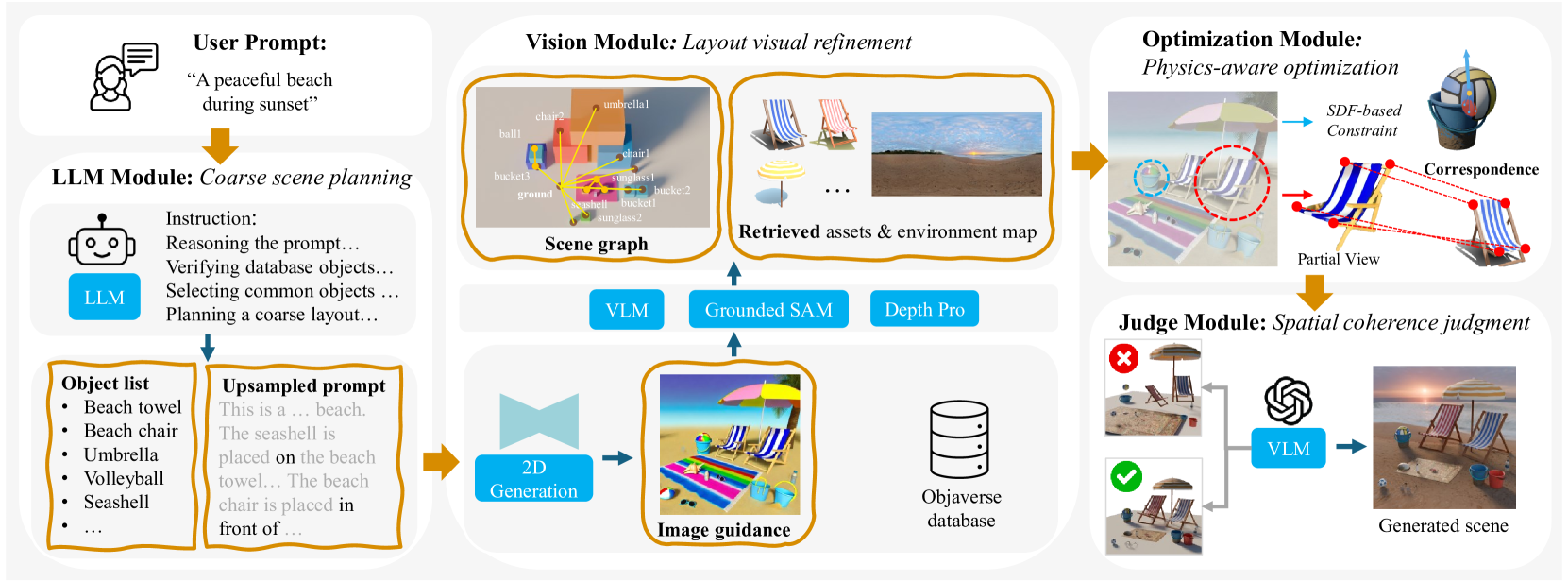
The complete Scenethesis pipeline from input prompt to final 3D scene.
Evaluation Highlights
- Outperforms Holodeck and PhyScene in physical plausibility, significantly reducing collision rates and instability
- Demonstrates superior scene diversity by generating valid outdoor scenes (e.g., beaches) which dataset-dependent baselines cannot handle
- Achieves higher layout realism and object interactivity scores in human evaluations compared to SOTA methods
Breakthrough Assessment
8/10
Significant advance in bridging the gap between text reasoning and 3D spatial reality without training. The move from bounding boxes to SDFs for layout optimization enables much more realistic object containment.