📝 Paper Summary
Efficient Long-Context Inference
Hierarchical Sequence Modeling
PHOTON replaces standard horizontal token-by-token scanning with a vertical, multi-resolution hierarchy that maintains a coarse global state and decodes fine-grained tokens in parallel local windows to reduce KV cache traffic.
Core Problem
Standard Transformers operate as horizontal scanners where every new token attends to an ever-growing history, making long-context decoding memory-bound due to massive KV cache reads/writes.
Why it matters:
- Inference latency for long contexts is dominated by memory bandwidth (moving large KV caches) rather than arithmetic computation
- KV cache size grows linearly with context length, creating a bottleneck for high-throughput serving in multi-query environments
Concrete Example:
In a standard Transformer generating a long document, generating the 10,000th token requires reading the keys/values for all 9,999 previous tokens from memory. PHOTON avoids this by only reading a compressed coarse state and a small local window.
Key Novelty
Parallel Hierarchical Operation for TOp-down Networks (PHOTON)
- Constructs a hierarchy of latent streams: a bottom-up encoder compresses tokens into coarse states, and lightweight top-down decoders reconstruct fine-grained tokens in parallel using bounded local attention
- Recursive Generation (RecGen): Updates only the coarsest latent stream during generation using decoder-side summaries, eliminating the need to re-encode new tokens from the bottom up
Architecture
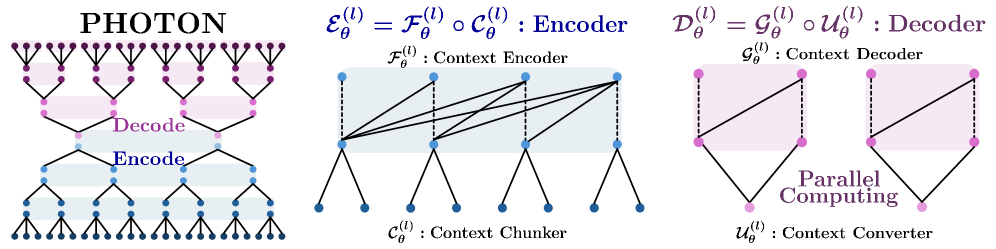
Conceptual comparison between Standard Transformer (Horizontal Scanning) and PHOTON (Vertical Scanning). It illustrates PHOTON's hierarchy with Bottom-Up Encoding and Top-Down Decoding.
Evaluation Highlights
- Achieves up to 10^3x higher throughput per unit of memory compared to vanilla Transformers by drastically reducing decode-time KV-cache traffic
- Outperforms Block Transformer on the throughput-quality Pareto frontier, offering better generation quality at similar or higher speeds
- Maintains constant O(1) local attention complexity per generated token regarding sequence length T, while global complexity scales with compressed sequence length
Breakthrough Assessment
8/10
Significant architectural departure from standard Transformers that addresses the critical memory-bandwidth bottleneck in long-context decoding. The recursive generation mechanism is a clever solution to the re-encoding problem inherent in hierarchical models.