📝 Paper Summary
Inference-time alignment
Agentic workflow optimization
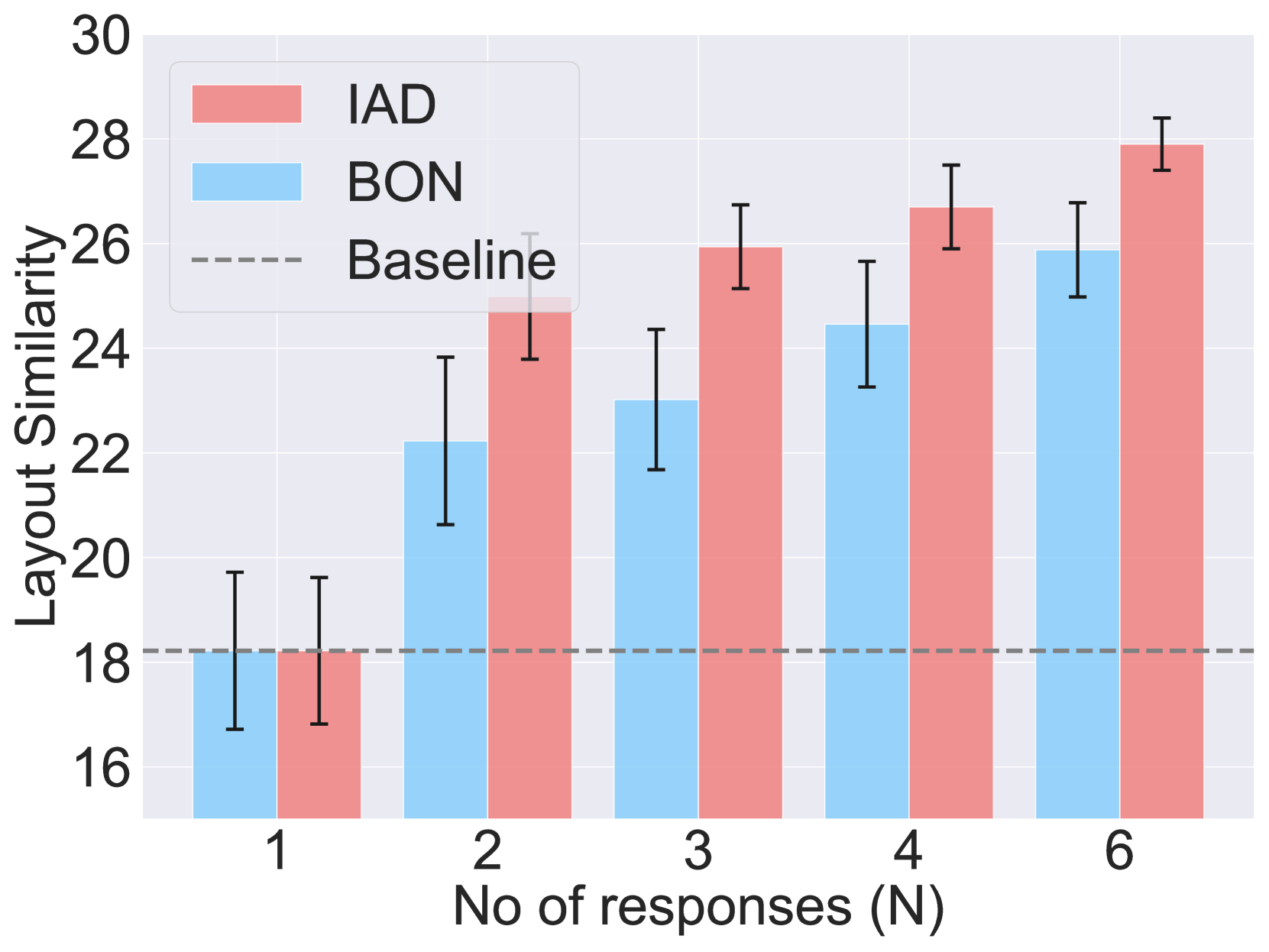
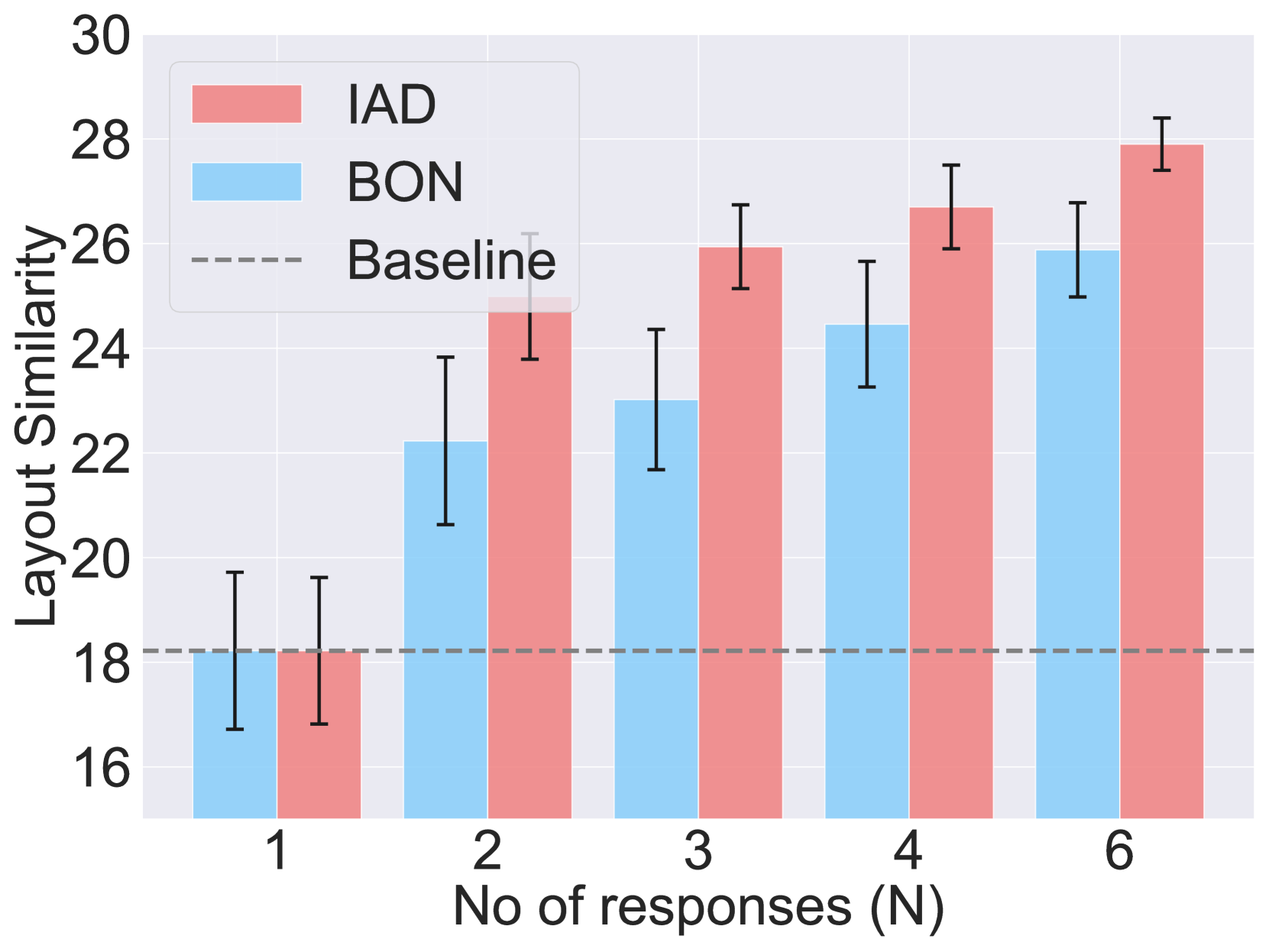
Iterative Agent Decoding (IAD) integrates scalar and textual feedback to iteratively refine agent outputs during inference, outperforming sampling-only methods like Best-of-N particularly under fixed compute budgets.
Core Problem
Agentic AI systems struggle with complex tasks (20-30% accuracy) and standard sampling methods like Best-of-N (BoN) are compute-inefficient because they cannot iteratively improve candidates based on past failures.
Why it matters:
- Current state-of-the-art agents fail frequently on benchmarks like Sketch2Code and Text2SQL, limiting real-world utility.
- Post-training methods (RLHF/SFT) are often inapplicable to black-box models or commercial APIs where internals are inaccessible.
- Simple parallel sampling (BoN) trades compute for latency but hits diminishing returns; it doesn't learn from mistakes within the inference window.
Concrete Example:
In a Text2SQL task, a model might generate a query with a syntax error. A standard sampler just generates a new, independent guess. IAD uses a verifier to identify the error, feeds that critique back into the prompt, and guides the model to fix the specific syntax issue in the next step.
Key Novelty
Iterative Agent Decoding (IAD)
- Framework that sequentially samples, evaluates, and integrates feedback to refine outputs, explicitly conditioning the next generation on the best previous solution and specific critiques.
- Converts scalar rewards (numerical scores) into structured textual prompts (e.g., 'Surpass the best response, avoid previous mistakes') to guide black-box models without access to gradients.
- Systematically analyzes the trade-off between parallel sampling (BoN) and sequential feedback-driven refinement under fixed compute budgets.
Architecture
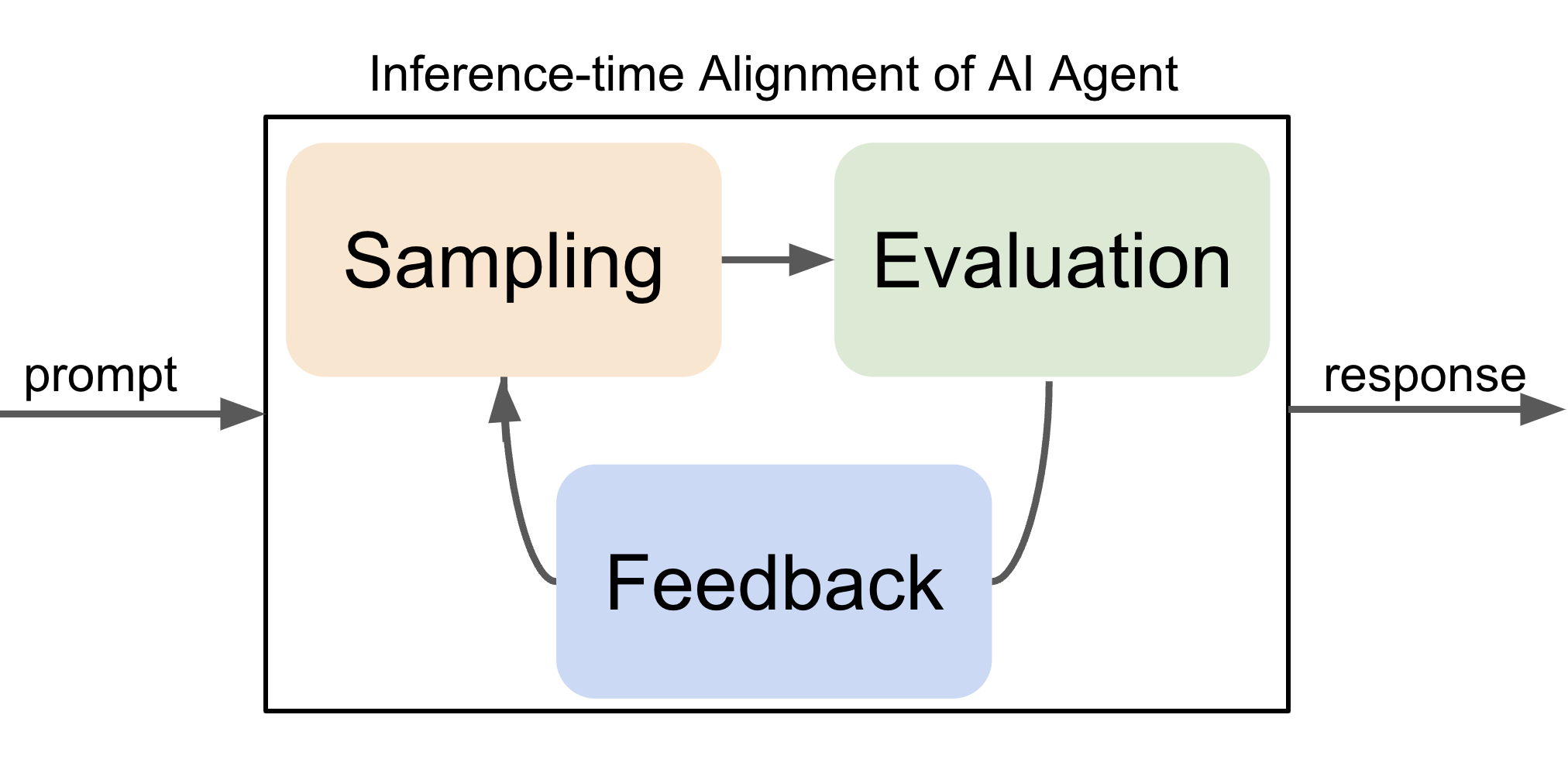
Illustration of the inference-time alignment loop comparing standard methods to IAD.
Evaluation Highlights
- Achieves up to 10% absolute performance improvement over Best-of-N and other baselines on Sketch2Code, Text2SQL, Intercode, and WebShop under constrained budgets.
- Demonstrates 4–8% gains specifically from feedback-guided refinement (isolating gains beyond sampling diversity) in Sketch2Code and Text2SQL.
- Transforming scalar feedback into directional prompts yields 6–7% gains over baselines that simply append scores, proving the importance of feedback design.
Breakthrough Assessment
7/10
Provides a strong, systematic empirical study on inference-time scaling for agents, offering a practical framework (IAD) that works with black-box models. While the concept of feedback isn't new, the rigorous quantification of compute vs. accuracy trade-offs is valuable.