📝 Paper Summary
Cross-lingual RAG
Benchmark Construction
XRAG is a benchmark for evaluating LLMs in cross-lingual RAG settings, revealing significant failures in response language correctness and cross-lingual reasoning even for advanced models like GPT-4o.
Core Problem
Existing cross-lingual QA datasets contain simple questions often answerable without retrieval, failing to evaluate complex reasoning in realistic RAG scenarios where user and document languages differ.
Why it matters:
- Real-world RAG systems must serve non-English users using English knowledge bases (monolingual retrieval) or a mix of local and English sources (multilingual retrieval)
- Current benchmarks like XOR QA allow models to answer nearly 50% of questions using parametric knowledge alone, masking true retrieval-reasoning failures
- Absence of challenging benchmarks prevents understanding of specific cross-lingual failure modes, such as responding in the wrong language or failing to integrate multi-language evidence
Concrete Example:
A German user asks a question about the 2024 Olympics. The relevant information is split between a German article and an English article. Current LLMs might fail to combine these facts or erroneously answer in English instead of German.
Key Novelty
XRAG Benchmark Construction Pipeline
- Generates questions from recent news (post-knowledge-cutoff) to ensure models cannot answer from parametric memory
- Uses a multi-step LLM workflow to create 'cross-document' questions that require integrating information from two distinct articles (supporting evidence) while ignoring distractors
- Covers two specific settings: Monolingual Retrieval (non-English question, English docs) and Multilingual Retrieval (non-English question, mixed-language docs)
Architecture
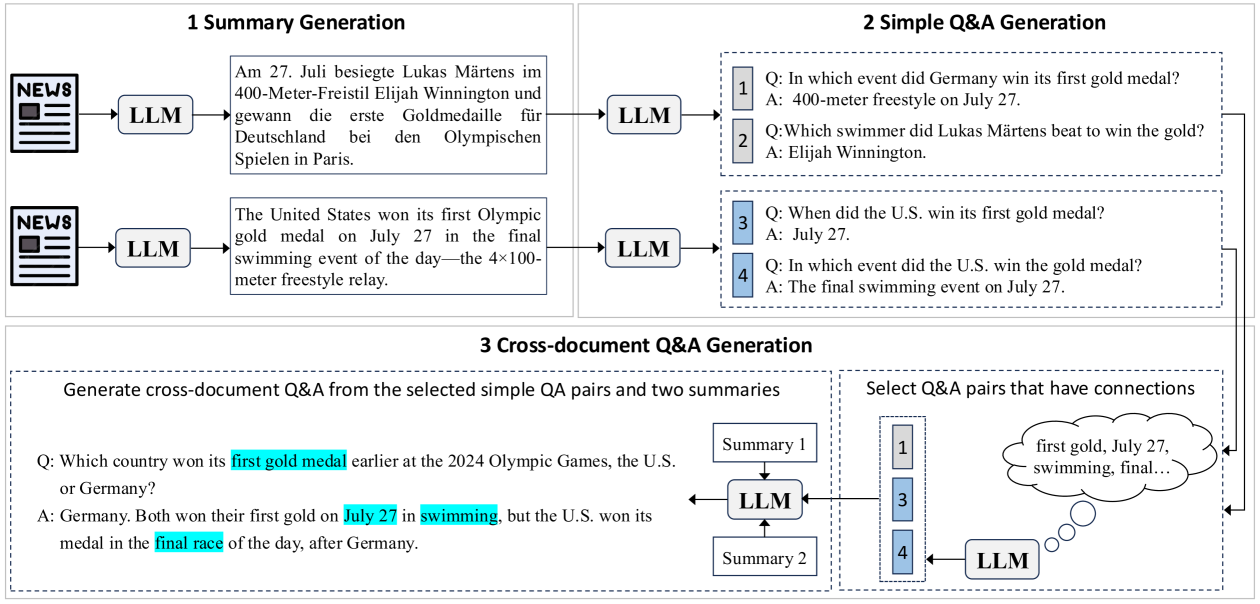
The data construction pipeline for generating cross-document QA pairs.
Evaluation Highlights
- In Monolingual Retrieval, GPT-4o achieves only 55.5% accuracy, significantly lower than the 85% human upper bound
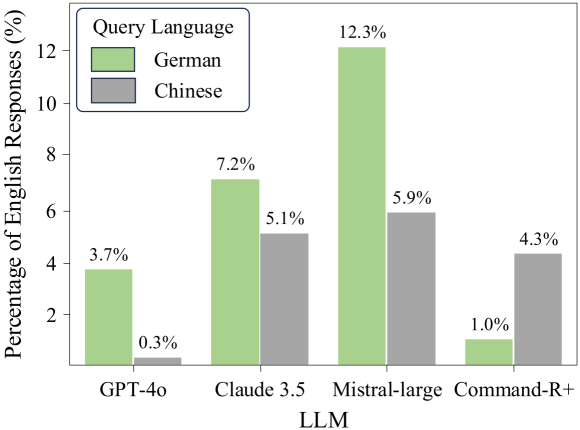
- Models struggle with Response Language Correctness (RLC): Mistral-large answers in the wrong language (English instead of user language) in 61.1% of cases
- In Multilingual Retrieval, translating supporting documents to English improves GPT-4o accuracy by ~9.5 percentage points, indicating the core bottleneck is cross-lingual reasoning, not generation
Breakthrough Assessment
8/10
Identifies a critical gap in cross-lingual RAG evaluation (parametric leakage in old benchmarks) and uncovers a major, previously under-reported failure mode (Response Language Correctness). High utility for future RAG research.