📝 Paper Summary
Benchmark datasets
Multi-call tool use with flexible plan
CORE-Bench evaluates AI agents on their ability to computationally reproduce results from published scientific papers by executing code and retrieving specific outputs from Dockerized environments.
Core Problem
Verifying computational reproducibility is critical for science but labor-intensive, and current AI agents lack benchmarks measuring their ability to perform this real-world task.
Why it matters:
- Computational reproducibility is fundamental to science, yet studies across fields (psychology, medicine, CS) show severe shortcomings where papers are irreproducible despite available code
- Current coding benchmarks (HumanEval) focus on toy problems, failing to capture the complexity of real-world research tasks like library installation, debugging, and figure interpretation
- Before agents can automate novel research, they must prove they can reproduce existing work, a necessary step often assumed but not tested
Concrete Example:
A researcher needs to verify a paper's claim. They attempt to run the provided code but fail because the software libraries are version-incompatible or the instructions assume a specific operating system. An agent on CORE-Bench faces this exact scenario: it must install dependencies, debug execution errors, and extract a specific numerical result from a generated PDF or plot.
Key Novelty
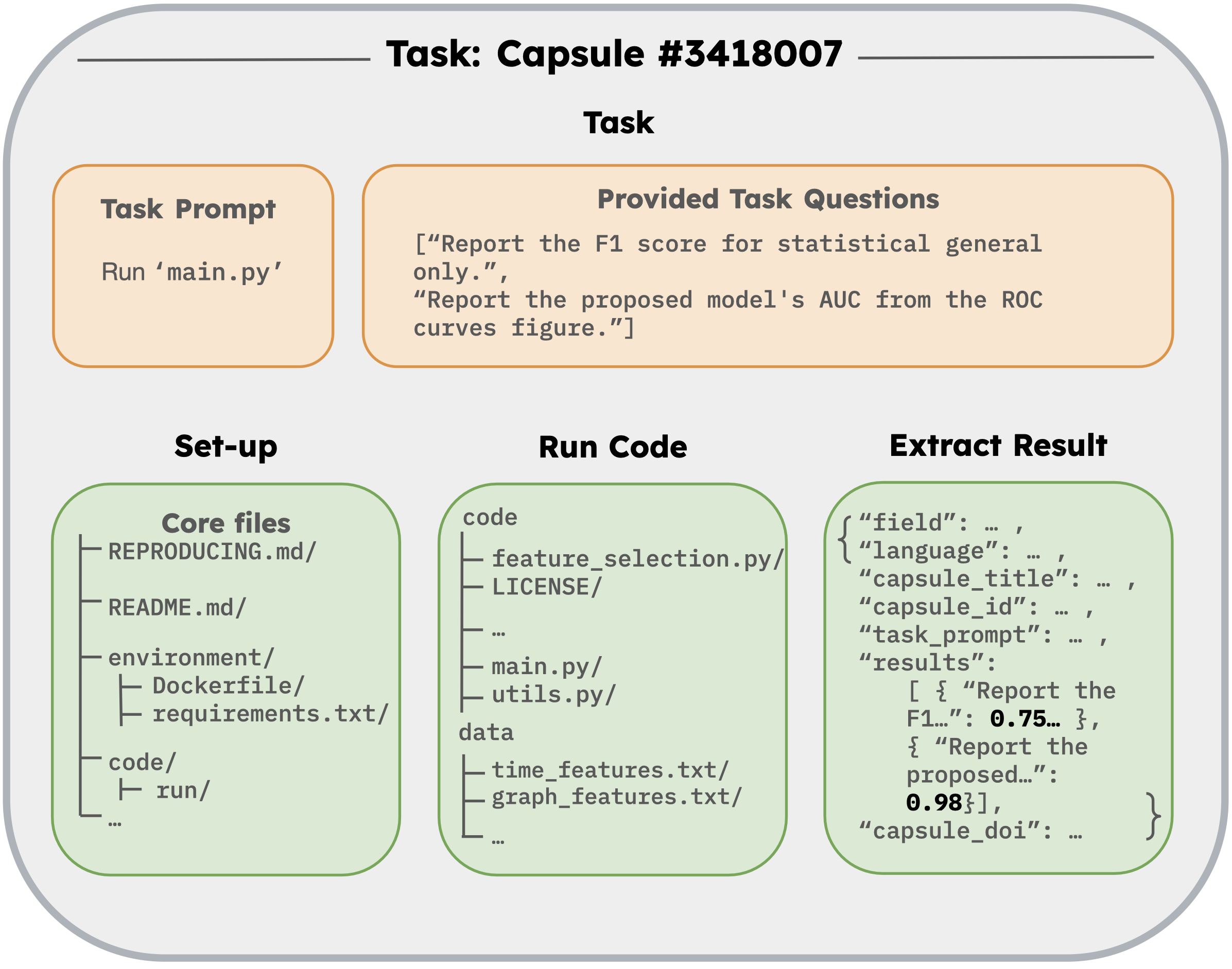
Realistic Reproducibility Benchmark based on Containerized Environments
- Builds tasks from CodeOcean capsules (verified reproducible compute environments) rather than synthetic coding problems, ensuring construct validity
- Evaluates agents across three difficulty levels: traversing a finished environment, executing provided Docker instructions, and building the environment from a Readme alone
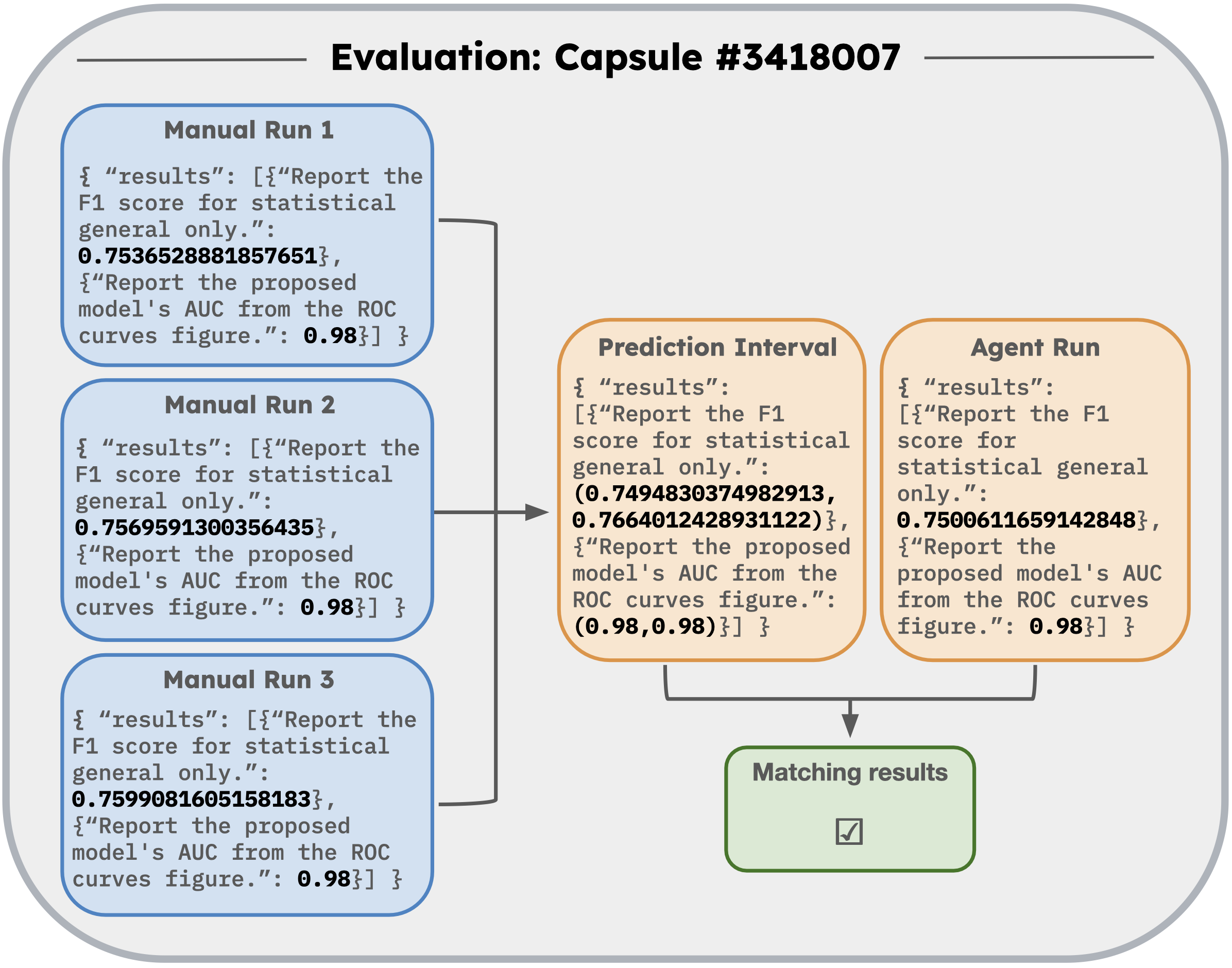
- Includes both text-based tasks (extracting numbers from logs) and vision-based tasks (interpreting generated plots/figures)
Architecture
The evaluation harness architecture showing the Manager-Worker separation
Evaluation Highlights
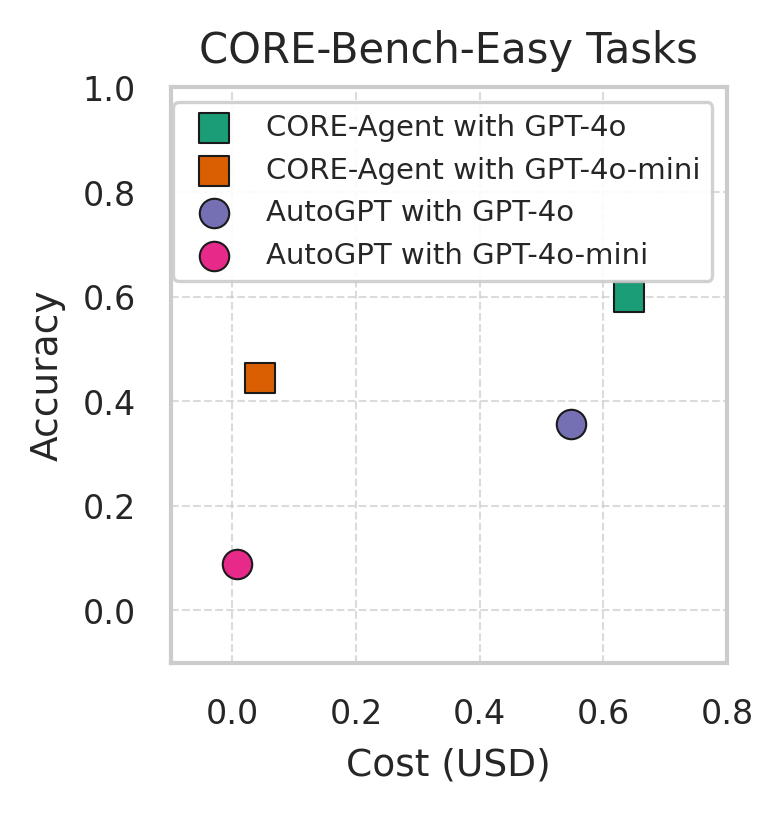
- Task-specific CORE-Agent with GPT-4o achieves 60.00% accuracy on the easiest level but drops to 21.48% on the hardest level
- GPT-4o agents consistently outperform GPT-4o-mini agents (e.g., 21.48% vs 16.30% on Hard tasks)
- Generalist AutoGPT agents perform poorly without task-specific prompting, scoring only 6.7% on Hard tasks compared to CORE-Agent's 21.5%
Breakthrough Assessment
8/10
Significant contribution to agentic evaluation. Moves beyond toy coding problems to real-world scientific workflows. The gap between easy (60%) and hard (21%) tasks highlights a clear frontier for future agent development.