📝 Paper Summary
Infrastructure cost of AI agents
Test-time scaling efficiency
Deploying dynamic reasoning agents drastically increases computational costs and latency variance compared to static models, with diminishing returns in accuracy that threaten infrastructure sustainability.
Core Problem
Dynamic reasoning agents (like ReAct or LATS) introduce iterative execution patterns involving multiple LLM calls and tool interactions, creating massive, uncharacterized burdens on serving infrastructure.
Why it matters:
- Prior architecture research focuses on static LLM inference, missing the unique bottlenecks of agentic workloads (e.g., control-flow serialization, context bloat)
- Without optimization, per-request costs could rise by orders of magnitude, making large-scale agent deployment economically and environmentally prohibitive (requiring gigawatt-scale data centers)
Concrete Example:
While a static Chain-of-Thought request uses 1 LLM call, a LATS (Language Agent Tree Search) agent requires an average of 71.0 LLM calls per request to solve the same task, causing extreme latency spikes.
Key Novelty
First System-Level Characterization of AI Agent Infrastructure
- Quantifies the 'serving cost' of dynamic reasoning by measuring end-to-end latency, energy, and resource utilization across five representative agent workflows
- Identifies unique infrastructure bottlenecks in agentic workloads, such as low GPU utilization due to serial tool dependencies and 'context bloat' from iterative history
- Analyzes the accuracy-cost Pareto frontier, revealing that advanced agents (like LATS) often incur 30x higher costs for marginal accuracy gains
Architecture
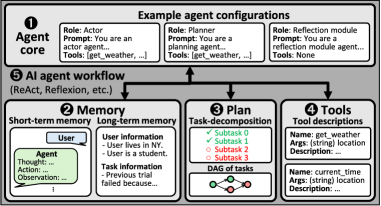
Overview of AI Agent Core Components and Workflows
Evaluation Highlights
- LATS (Language Agent Tree Search) incurs ~71x more LLM calls per request than CoT (Chain-of-Thought) on average, illustrating the massive compute amplification of test-time scaling
- Tool execution can dominate latency; in HotpotQA, tool calls account for significant time due to 1.2s average API latency, causing GPU underutilization during wait times
- Advanced agents suffer from severe diminishing returns; e.g., scaling to LATS typically yields small accuracy gains while increasing cost and energy consumption by over an order of magnitude
Breakthrough Assessment
8/10
Highly significant for the systems/infrastructure community. It shifts the focus from 'how to build better agents' to 'how to afford running them,' providing the first rigorous quantification of the looming sustainability crisis.

