📝 Paper Summary
Multi-agent
Self-evolving Agentic reasoning
Curie is an agentic framework that automates scientific experimentation by enforcing rigor through modular validation (Intra-ARM) and structured coordination (Inter-ARM) between architect and technician agents.
Core Problem
Existing AI agents for science rely on ad-hoc prompts and lack the rigor required for reliable experimentation, leading to hallucinations, unverified procedures, and non-reproducible results.
Why it matters:
- Reckless or unverified AI experimentation generates untrustworthy findings, potentially polluting scientific literature with hallucinated results
- Current LLM-based research assistants excel at literature review but fail at methodical execution (e.g., setting up controlled variables, handling dependencies)
- Without structured oversight, errors in early experimental stages (like environment setup) propagate, wasting resources and compromising final conclusions
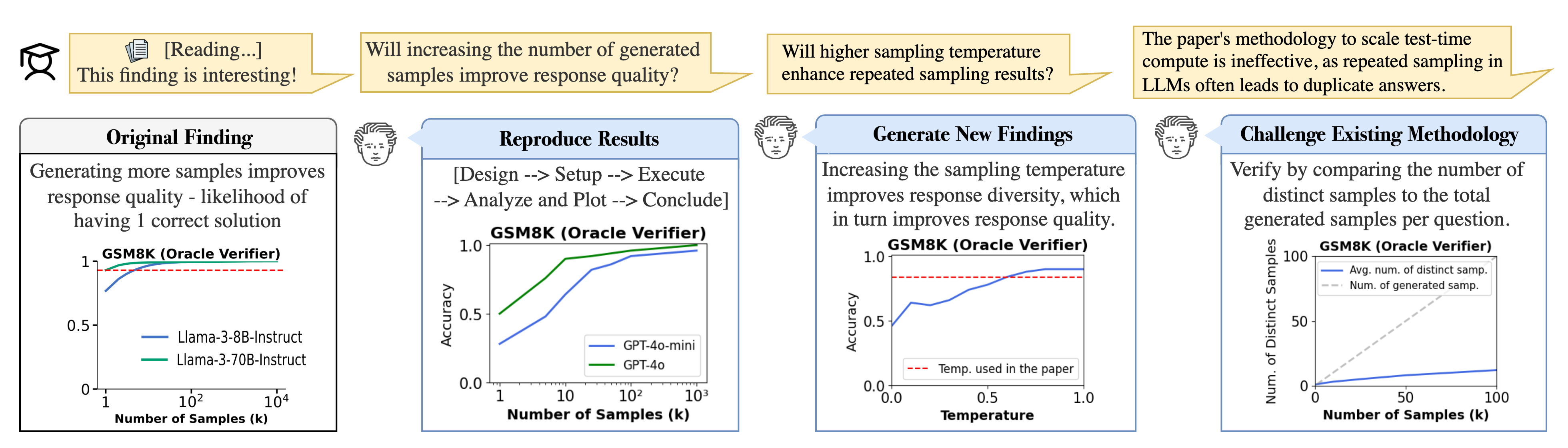
Concrete Example:
When asked to reproduce a specific distributed systems experiment, a standard coding agent might generate a script that hardcodes variables or skips dependency checks. Curie's validator would catch the hardcoded values, force the agent to parameterize them, and verify the setup runs in a clean environment before allowing full execution.
Key Novelty
Experimental Rigor Engine (Intra-ARM & Inter-ARM)
- Injects a 'supervisor' loop between planning and execution: an Intra-Agent Rigor Module (Intra-ARM) intercepts agent actions to validate them against specific policies (e.g., reproducibility checks) before proceeding
- Uses an Inter-Agent Rigor Module (Inter-ARM) to break large experimental plans into independent partitions and schedule them, preventing the chaotic execution typical of naive multi-agent conversations
Architecture
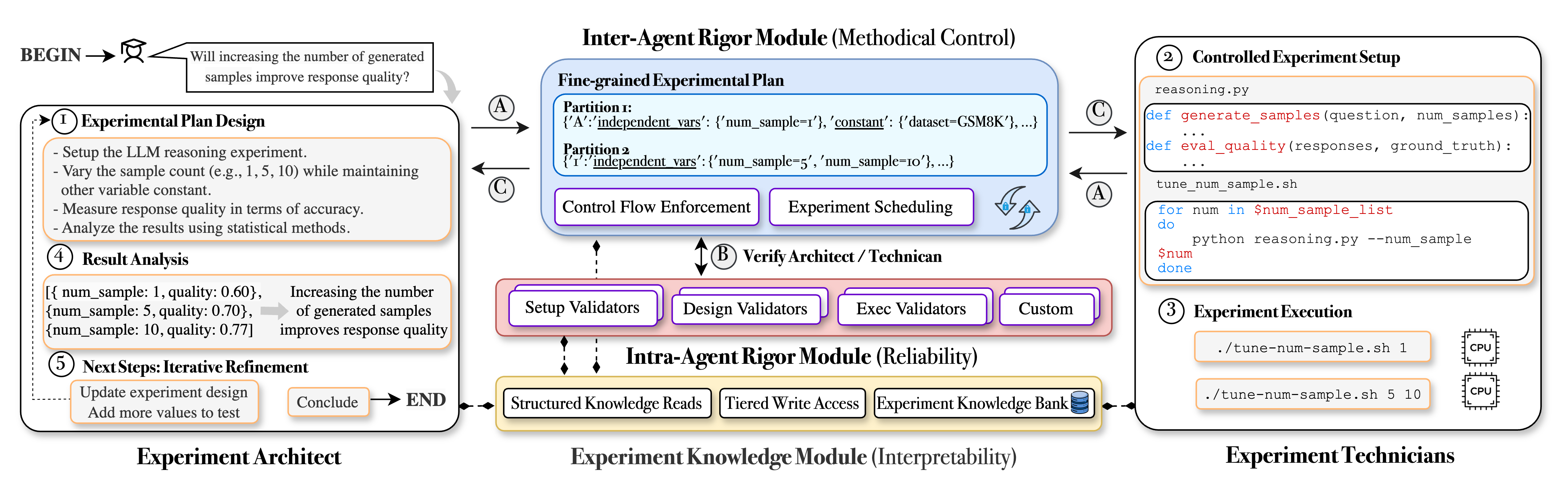
The complete Curie architecture, showing the interaction between the Architect, Technicians, Inter-ARM, Intra-ARM, and the Experiment Knowledge Module.
Evaluation Highlights
- 3.4× improvement in correctly answering experimental questions compared to OpenHands (a state-of-the-art coding agent) on the new Experimentation Benchmark
- Significantly outperforms Microsoft Magentic (generalist multi-agent system) on complex tasks involving reproduction and extension of research papers
- Introduces a new benchmark of 46 rigorous tasks derived from real-world CS research papers and open-source projects
Breakthrough Assessment
8/10
Strong conceptual contribution in formalizing 'rigor' for agents via explicit validation modules. The 3.4x gain is impressive, though the benchmark is relatively small (46 tasks) and domain-specific (CS research).