📝 Paper Summary
Self-evolving Agentic reasoning
Multi-task planning
ML-Master is an automated AI engineering agent that integrates Monte Carlo Tree Search exploration with LLM-based reasoning via an adaptive memory mechanism to solve complex machine learning tasks.
Core Problem
Existing AI-for-AI agents either explore inefficiently without deep reasoning or reason without sufficient exploration history, leading to hallucinations, stagnation, and inability to leverage past trial-and-error experiences.
Why it matters:
- Developing effective AI solutions is inherently iterative; current agents struggle to distill past failures into future success
- Pure exploration leads to aimless trial-and-error, while pure reasoning risks stagnation or hallucination due to lack of empirical feedback
- Reasoning models (like DeepSeek-R1) are often overwhelmed by long, unstructured contexts if all exploration history is fed blindly
Concrete Example:
In a Kaggle competition task, a standard agent might repeatedly try the same buggy code fix or hallucinate a library function because it forgets previous error logs. ML-Master uses structured memory to recall that 'Method A failed with Error X' and steers the reasoning model to try 'Method B' instead.
Key Novelty
Coupling Steerable Reasoning with Tree-Structured Exploration via Adaptive Memory
- Reformulates AI development as a Monte Carlo Tree Search (MCTS) where nodes are solution states and edges are actions like 'Debug' or 'Improve'
- Uses an adaptive memory mechanism to selectively feed only relevant insights and execution feedback from the search tree into the reasoning model, preventing context overflow
- Employes a 'steerable reasoning' module where the LLM explicitly reflects on this selective memory to guide the next exploration step
Architecture
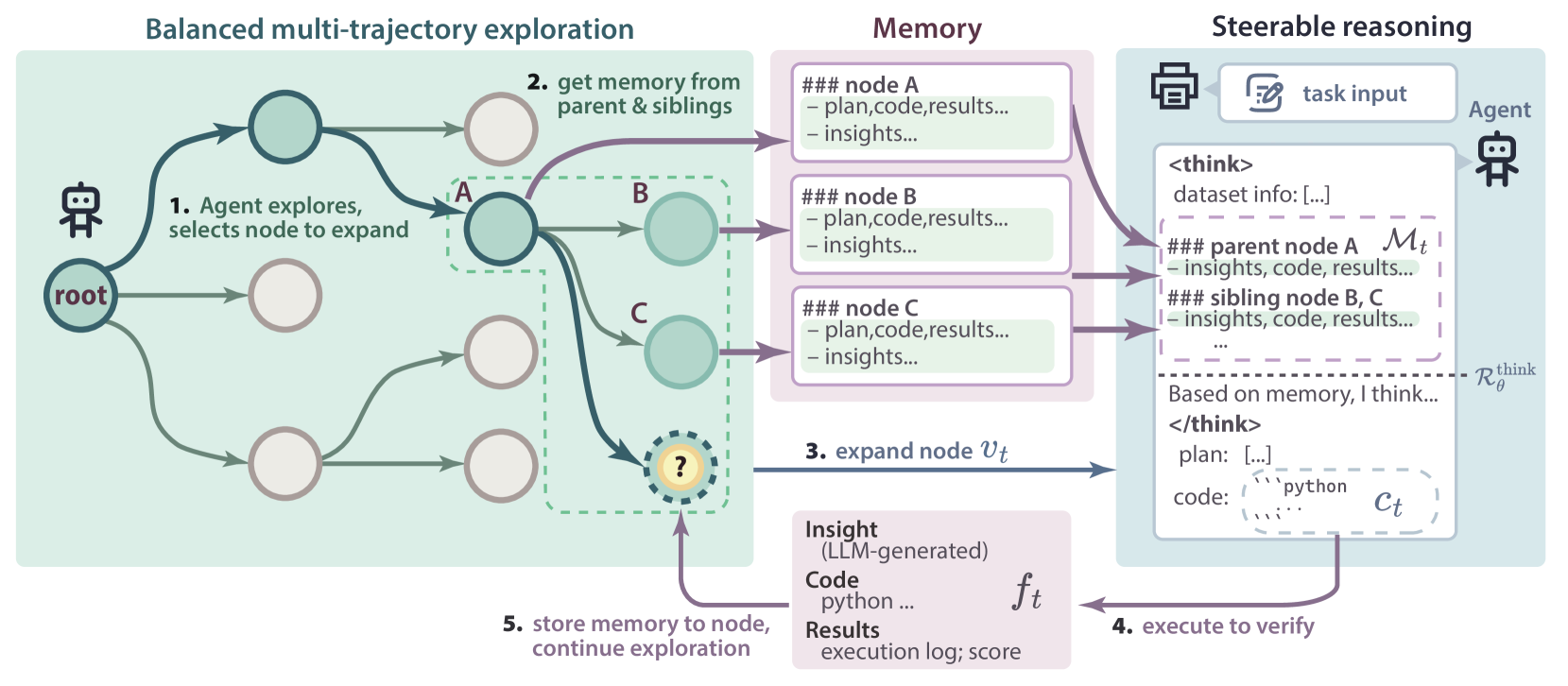
The overall framework of ML-Master, illustrating the interaction between the Balanced Multi-Trajectory Exploration module and the Steerable Reasoning module via Adaptive Memory.
Evaluation Highlights
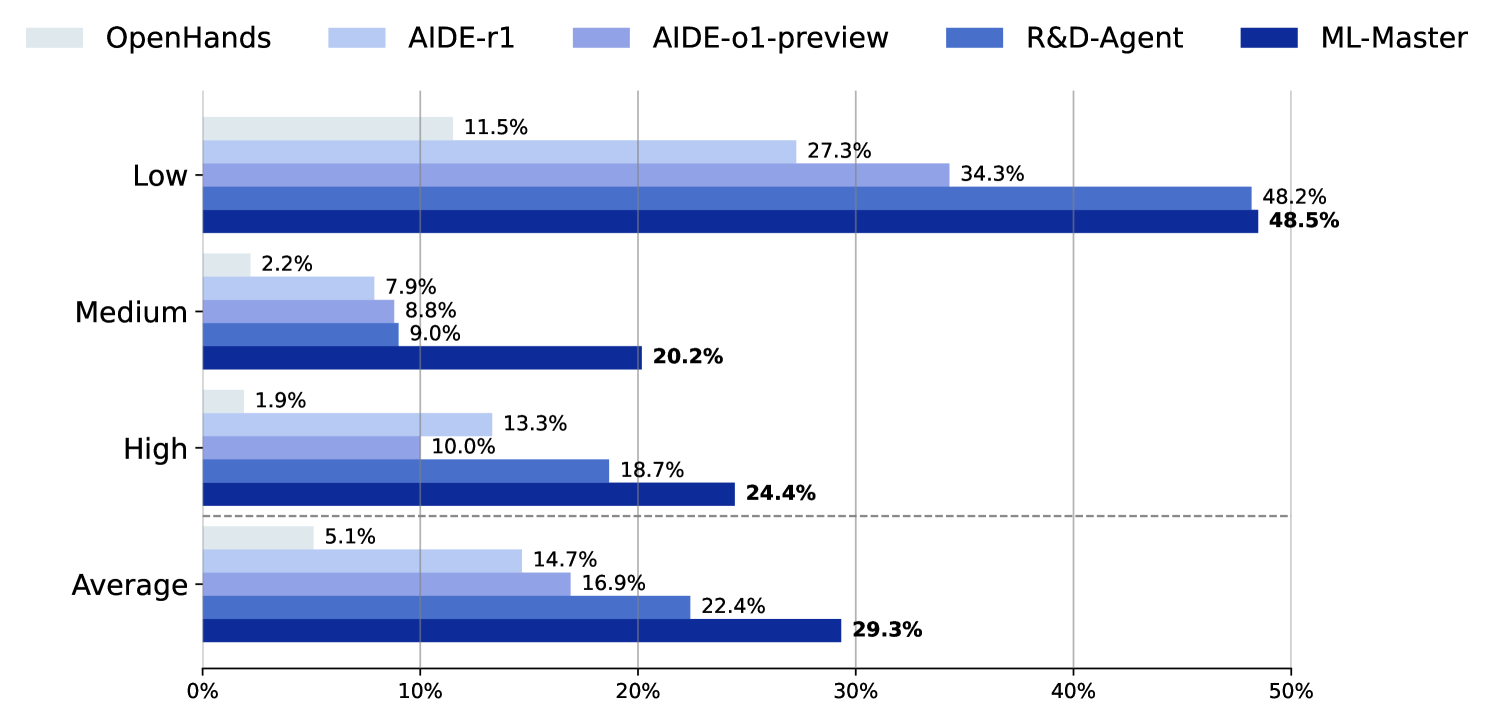
- Achieved 29.3% average medal rate on MLE-Bench, outperforming the strongest baseline (R&D-Agent) which scored 22.4%
- Surpassed previous bests significantly on medium-difficulty tasks, reaching a 20.2% medal rate compared to the prior best of 9.0%
- Accomplished these results within a 12-hour time constraint, half the 24-hour limit used by previous baselines
Breakthrough Assessment
8/10
Significantly advances automated machine learning by successfully integrating MCTS with LLM reasoning, achieving state-of-the-art on a difficult benchmark (MLE-Bench) with half the compute time.