📝 Paper Summary
Multi-call tool use with flexible plan
Multi-agent
Agentic reasoning
SciMaster achieves state-of-the-art performance on scientific benchmarks by using a scattered-and-stacked multi-agent workflow where models write and execute Python code to interact with external tools.
Core Problem
Existing strong reasoning models are either non-agentic (limited tool use) or closed-source (OpenAI o3, Google Deep Research), limiting community progress in applying AI to complex scientific discovery.
Why it matters:
- Closed-source nature of leading models (OpenAI, Google) prevents researchers from understanding or building upon the mechanisms for scientific problem solving
- Standard LLMs lack the ability to dynamically verify facts or perform complex calculations required for frontier scientific questions
- Accelerating scientific discovery requires agents that can autonomously navigate the internet and use libraries, mimicking human research workflows
Concrete Example:
When faced with a frontier scientific question from Humanity's Last Exam (HLE), a standard model might hallucinate or fail to retrieve up-to-date data. X-Master writes Python code to search the web, parse specific papers from ar5iv, and calculate answers using NumPy, correcting itself based on execution feedback.
Key Novelty
Scattered-and-Stacked Agentic Workflow (X-Masters)
- Concept: Scales inference-time compute by alternating between broad exploration ('scattering' via parallel solvers) and deep refinement ('stacking' via aggregation and selection)
- Mechanism: Uses 'Code as Interaction Language', where the model generates Python scripts to interact with tools (web search, paper parsing) rather than JSON or special tokens, allowing flexible feedback loops
- Guidance: Instead of training, uses 'Initial Reasoning Guidance' (injecting first-person self-statements into the context) to trick non-agentic models into adopting agentic behaviors
Architecture
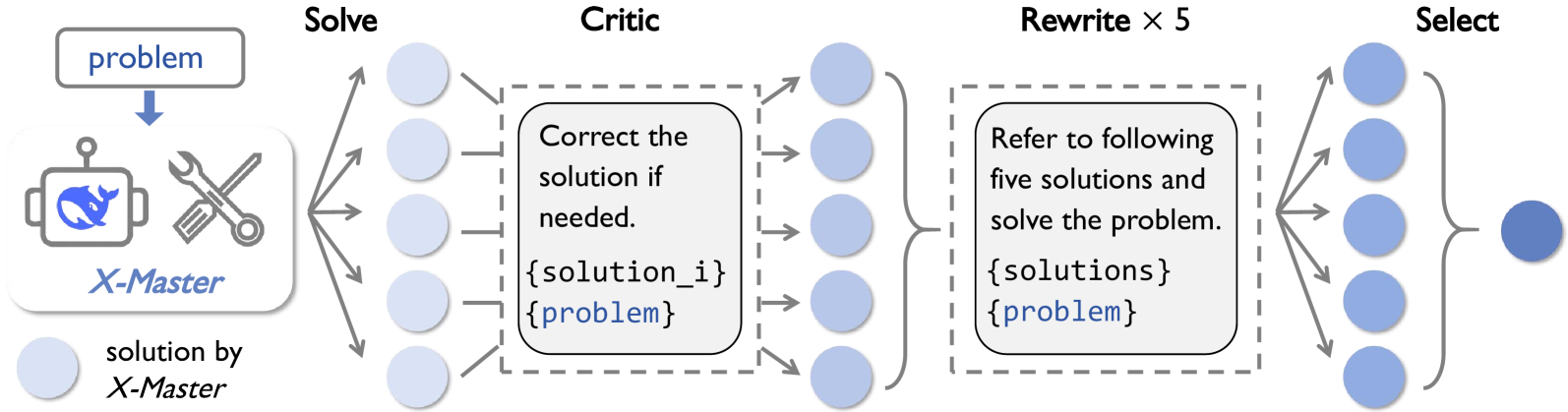
The X-Masters scattered-and-stacked workflow
Evaluation Highlights
- Achieves 32.1% on Humanity's Last Exam (HLE), setting a new state-of-the-art record
- Surpasses OpenAI's best result (26.6%) by 5.5 percentage points on HLE
- Outperforms Google's Deep Research (26.9%) by 5.2 percentage points on HLE
Breakthrough Assessment
9/10
First open-source model to beat OpenAI and Google on the extremely difficult HLE benchmark (passing the 30% threshold), demonstrating that inference-time scaling strategies can outperform proprietary black-box models.