📝 Paper Summary
AI Safety Survey
Adversarial Robustness
Model Alignment
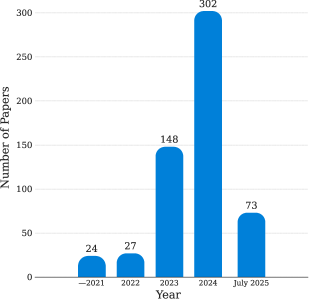
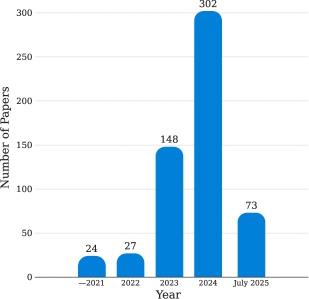
This survey establishes a comprehensive taxonomy of safety threats and defenses across six major large model categories—including VFMs, LLMs, and Agents—analyzing 574 papers to identify critical gaps in defense research.
Core Problem
The rapid deployment of large models in critical applications has introduced diverse safety risks (adversarial attacks, jailbreaks, data poisoning) that are currently studied in isolation, lacking a unified perspective.
Why it matters:
- Widespread deployment in healthcare and autonomous driving makes vulnerabilities (e.g., unintended behaviors, privacy leakage) physically and ethically dangerous
- Current defense research lags significantly behind attack research (~40% vs ~60%), leaving systems exposed
- Existing surveys are typically narrow, focusing only on single modalities like LLMs or specific threats like jailbreaking, missing the interconnected risks in multi-modal and agentic systems
Concrete Example:
In Vision Foundation Models (VFMs), a 'Patch-Fool' attack can perturb individual image patches to manipulate attention scores and alter decisions. Similarly, in Agents, 'indirect prompt injection' can occur when an agent processes a malicious webpage, causing it to execute harmful instructions unbeknownst to the user.
Key Novelty
Unified Safety Taxonomy across Modalities
- Integrates safety research for six distinct model types (VFMs, LLMs, VLPs, VLMs, DMs, Agents) under a single hierarchical framework
- Standardizes attack definitions (e.g., identifying 'jailbreak' counterparts in both LLMs and Diffusion Models)
- Explicitly categorizes Agent-specific threats (e.g., tool manipulation, memory corruption) which are often overlooked in general model surveys
Architecture
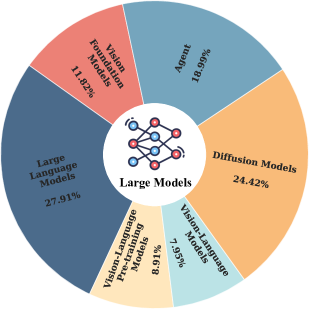
The hierarchical structure (Taxonomy) of the survey, organizing the field into Model Types -> Attack/Defense -> Specific Categories
Evaluation Highlights
- Analyzed 574 technical papers, with 71.32% focused on LLMs, DMs, and Agents
- Identified that research on attacks (~60%) significantly outweighs research on defenses (~40%)
- Taxonomy covers 10 distinct attack types including emerging threats like energy-latency attacks and agent memory injection
Breakthrough Assessment
9/10
A foundational reference work. It is likely the most comprehensive taxonomy to date, unifying disjoint fields (vision, language, agents) and providing a clear structured roadmap for future safety research.