📝 Paper Summary
Mobile UI Agents
Multi-Modal Large Language Models (MLLMs)
Multi-Agent Collaboration
Mobile-Agent-v2 employs a multi-agent architecture (Planning, Decision, Reflection) with a memory unit to solve navigation challenges and context length limitations in mobile device operations.
Core Problem
Single-agent MLLMs struggle with mobile device operations due to overly long, interleaved text-image history sequences and the difficulty of retaining focus content across multi-step tasks.
Why it matters:
- Long history sequences degrade MLLM performance, making it hard to track task progress
- Important information (focus content) from previous screens is often lost in long contexts, preventing successful completion of dependent sub-tasks
- Existing single-agent architectures lack robust error correction mechanisms when operations fail or hallucinate
Concrete Example:
In a task requiring writing sports news, an agent must first query match results. In single-agent setups, the lengthy history of searching for results obscures the actual scores when the agent finally attempts to write the news, causing it to fail or hallucinate the content.
Key Novelty
Multi-Agent Collaboration with Specialized Roles (Planning, Decision, Reflection)
- Decomposes the operation process into three agents: a Planner that summarizes history into text, a Decider that executes actions and updates memory, and a Reflector that verifies outcomes.
- Introduces a dedicated Memory Unit to store 'focus content' (task-relevant info like a weather forecast or match score) separately from the raw operation history, preventing information loss.
Architecture
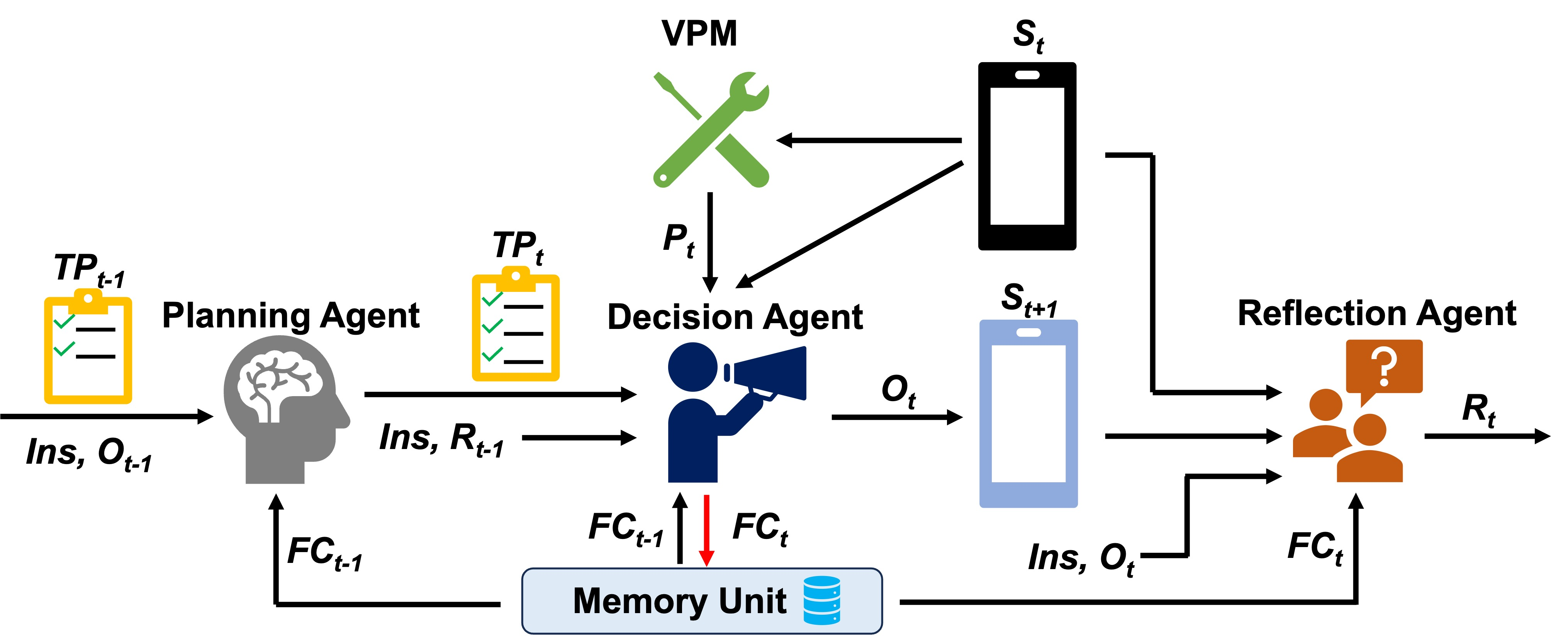
The iterative workflow of Mobile-Agent-v2 showing the interaction between the three agents (Planning, Decision, Reflection) and the Memory Unit.
Evaluation Highlights
- +30% improvement in task completion rate compared to the single-agent Mobile-Agent architecture
- Achieves >90% success rate on basic instruction following tasks (Mobile-Eval)
- Significantly reduces effective context length by condensing image-text history into pure-text task progress summaries
Breakthrough Assessment
8/10
Significant architectural advance by applying multi-agent patterns to mobile UI automation. Effectively solves the context-length bottleneck that plagues single-agent visual approaches.